Entry
Reader's guide
Entries A-Z
Subject index
Goodness-of-Fit Measures
Goodness-of-fit measures are statistics calculated from a sample of data, and they measure the extent to which the sample data are consistent with the MODEL being considered. Of the goodness-of-fit measures, R-SQUARED, also denoted R2, is perhaps the most well known, and it serves here as an initial example. In a LINEAR REGRESSION analysis, the VARIABLEY is approximated by a model, set equal to Ŷ, which is a linear combination of a set of kEXPLANATORY VARIABLES, Ŷ = +β^0 + β^1X1 + β^2X2 +…+ β^kXk. The COEFFICIENTS in the model, β^0, β^1, β^2,…, β^k, are estimated from the data so that the sum of the squared differences between Y and Ŷ is as small as possible, also called the SUM OF SQUARED ERRORS (SSE), SSE = Σ(Y − Ŷ)2. R2 gauges the goodness of fit between the observed variable Y and the regression model Ŷ and is defined as 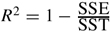 , where SST = Σ(Y − Y¯)2, which is the sum of the squared deviations around the sample mean Y¯. It ranges in value from 0, indicating extreme lack of fit, to 1, indicating perfect fit. It has universal appeal because it can be interpreted as the square of the CORRELATION between Y and Ŷ or as the proportion of the total variance in Y that is accounted for by the model.
, where SST = Σ(Y − Y¯)2, which is the sum of the squared deviations around the sample mean Y¯. It ranges in value from 0, indicating extreme lack of fit, to 1, indicating perfect fit. It has universal appeal because it can be interpreted as the square of the CORRELATION between Y and Ŷ or as the proportion of the total variance in Y that is accounted for by the model.
Additional Examples
Goodness-of-fit measures are not limited to regression models but may apply to any hypothetical statement about the study POPULATION. The following are three examples of models and corresponding goodness-of-fit measures.
The HYPOTHESIS that a variable X has a NORMAL DISTRIBUTION in the population is an example of a model. With a sample of observations on X, the goodness-of-fit statistic D can be calculated as a measure of how well the sample data conform to a normal distribution. In addition, the D statistic can be used in the KOLMOGOROV-SMIRNOV TEST to formally test the hypothesis that X is normally distributed in the population.
Another example of a model is the hypothesis that the mean, denoted μ, of the distribution of X is equal to 100, or μX = 100. The T-STATISTIC can be calculated from a sample of data to measure the goodness of fit between the sample mean X¯ and the hypothesized population mean μX. The t-statistic can then be used in a T-TEST to decide if the hypothesis μX = 100 should be rejected based on the sample data.
One more example is the INDEPENDENCE model, which states that two categorical variables are unrelated in the population. The numbers expected in each category of a CONTINGENCY TABLE of the sample data, if the independence model is true, are called the “EXPECTED FREQUENCIES,” and the numbers actually observed in the sample are called the “OBSERVED FREQUENCIES.” The goodness of fit between the hypothesized independence model and the sample data is measured with the χ2 (chi-square) statistic, which can then be used with the χ2 test (CHI-SQUARE TEST) to decide if the independence model should be rejected.
Hypothesis Tests
The examples above illustrate two distinct classes of goodness-of-fit measures that serve different purposes. Each summarizes the consistency between sample data and a model, but R2 is a descriptive statistic with a clear intuitive interpretation, whereas D,t, and χ2are INFERENTIAL STATISTICS that are less meaningful intrinsically. The inferential measures are valuable for conducting HYPOTHESIS TESTS about goodness of fit, principally because each has a known SAMPLING DISTRIBUTION that often has the same name as the statistic (e.g., t and χ2). Even if a model accurately represents the population under study, a goodness-of-fit statistic calculated from a sample of data will rarely indicate a perfect fit with the model, and the extent of departure from perfect fit will vary from one sample to another. This variation is captured in the sampling distribution of a goodness-of-fit measure, which is known for D,t, and χ2. These statistics become interpretable as measures of fit when compared to their sampling distribution, so that if the sample statistic lies sufficiently far out in the tail of its sampling distribution, it suggests that the sample data are improbable if the model is true (i.e., a poor fit between data and model). Depending on the rejection criteria for the test and the SIGNIFICANCE LEVEL chosen, the sample statistic may warrant rejection of the proposed model.
...
- Analysis of Variance
- Association and Correlation
- Association
- Association Model
- Asymmetric Measures
- Biserial Correlation
- Canonical Correlation Analysis
- Correlation
- Correspondence Analysis
- Intraclass Correlation
- Multiple Correlation
- Part Correlation
- Partial Correlation
- Pearson's Correlation Coefficient
- Semipartial Correlation
- Simple Correlation (Regression)
- Spearman Correlation Coefficient
- Strength of Association
- Symmetric Measures
- Basic Qualitative Research
- Basic Statistics
- F Ratio
- N(n)
- t-Test
- X¯
- Y Variable
- z-Test
- Alternative Hypothesis
- Average
- Bar Graph
- Bell-Shaped Curve
- Bimodal
- Case
- Causal Modeling
- Cell
- Covariance
- Cumulative Frequency Polygon
- Data
- Dependent Variable
- Dispersion
- Exploratory Data Analysis
- Frequency Distribution
- Histogram
- Hypothesis
- Independent Variable
- Measures of Central Tendency
- Median
- Null Hypothesis
- Pie Chart
- Regression
- Standard Deviation
- Statistic
- Causal Modeling
- Discourse/Conversation Analysis
- Econometrics
- Epistemology
- Ethnography
- Evaluation
- Event History Analysis
- Experimental Design
- Factor Analysis and Related Techniques
- Feminist Methodology
- Generalized Linear Models
- Historical/Comparative
- Interviewing in Qualitative Research
- Latent Variable Model
- Life History/Biography
- Log-Linear Models (Categorical Dependent Variables)
- Longitudinal Analysis
- Mathematics and Formal Models
- Measurement Level
- Measurement Testing and Classification
- Multilevel Analysis
- Multiple Regression
- Qualitative Data Analysis
- Sampling in Qualitative Research
- Sampling in Surveys
- Scaling
- Significance Testing
- Simple Regression
- Survey Design
- Time Series
- ARIMA
- Box-Jenkins Modeling
- Cointegration
- Detrending
- Durbin-Watson Statistic
- Error Correction Models
- Forecasting
- Granger Causality
- Interrupted Time-Series Design
- Intervention Analysis
- Lag Structure
- Moving Average
- Periodicity
- Serial Correlation
- Spectral Analysis
- Time-Series Cross-Section (TSCS) Models
- Time-Series Data (Analysis/Design)
- Trend Analysis
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches