Entry
Reader's guide
Entries A-Z
Subject index
Generalizability Theory
Generalizability theory provides an extensive conceptual framework and set of statistical machinery for quantifying and explaining the consistencies and inconsistencies in observed scores for objects of measurement. To an extent, the theory can be viewed as an extension of classical test theory through the application of certain ANALYSIS OF VARIANCE (ANOVA) procedures. Classical theory postulates that an observed score can be decomposed into a TRUE SCORE and a single undifferentiated random error term. By contrast, generalizability theory substitutes the notion of universe score for true score and liberalizes classical theory by employing ANOVA methods that allow an investigator to untangle the multiple sources of error that contribute to the undifferentiated error in classical theory.
Perhaps the most important and unique feature of generalizability theory is its conceptual framework, which focuses on certain types of studies and universes. A generalizability (G) study involves the collection of a sample of data from a universe of admissible observations that consists of facets defined by an investigator. Typically, the principal result of a G study is a set of estimated random-effects variance components for the universe of admissible observations. A D (decision) study provides estimates of universe score variance, error variances, certain indexes that are like RELIABILITY COEFFICIENTS, and other statistics for a measurement procedure associated with an investigator-specified universe of generalization.
In univariate generalizability theory, there is only one universe (of generalization) score for each object of measurement. In multivariate generalizability theory, each object of measurement has multiple universe scores. Univariate generalizability theory typically employs random-effects models, whereas MIXED-EFFECTS MODELS are more closely associated with multivariate generalizability theory.
Historical Development
The defining treatment of generalizability theory is the 1972 book by Lee J. Cronbach, Goldine C. Gleser, Harinder Nanda, and Nageswari Rajaratnam titled The Dependability of Behavioral Measurements. A recent extended treatment of the theory is the 2001 book by Robert L. Brennan titled Generalizability Theory. The essential features of univariate generalizability theory were largely completed with technical reports in 1960–1961 that were revised into three journal articles, each with a different first author (Cronbach, Gleser, and Rajaratnam). Multivariate generalizability theory was developed during the ensuing decade. Research between 1920 and 1955 by Ronald A. Fisher, Cyril Burt, Cyril J. Hoyt, Robert L. Ebel, and E. F. Lindquist, among others, influenced the development of generalizability theory.
Example
Suppose an investigator, Smith, wants to construct a measurement procedure for evaluating writing proficiency. First, Smith might identify or characterize essay prompts of interest, as well as potential raters. Doing so specifies the facets in the universe of admissible observations. Assume these facets are viewed as infinite and that, in theory, any person p (i.e., object of measurement) might respond to any essay prompt t, which in turn might be evaluated by any rater r. If so, a likely data collection design might be p × t × r, where “×” is read as “crossed with.” The associated linear model is
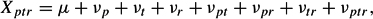
where the ν are uncorrelated score effects. This model leads to
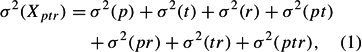
which is a decomposition of the total observed score variance into seven variance components that are usually estimated using the expected MEAN SQUARES in a random-effects ANOVA.
...
- Analysis of Variance
- Association and Correlation
- Association
- Association Model
- Asymmetric Measures
- Biserial Correlation
- Canonical Correlation Analysis
- Correlation
- Correspondence Analysis
- Intraclass Correlation
- Multiple Correlation
- Part Correlation
- Partial Correlation
- Pearson's Correlation Coefficient
- Semipartial Correlation
- Simple Correlation (Regression)
- Spearman Correlation Coefficient
- Strength of Association
- Symmetric Measures
- Basic Qualitative Research
- Basic Statistics
- F Ratio
- N(n)
- t-Test
- X¯
- Y Variable
- z-Test
- Alternative Hypothesis
- Average
- Bar Graph
- Bell-Shaped Curve
- Bimodal
- Case
- Causal Modeling
- Cell
- Covariance
- Cumulative Frequency Polygon
- Data
- Dependent Variable
- Dispersion
- Exploratory Data Analysis
- Frequency Distribution
- Histogram
- Hypothesis
- Independent Variable
- Measures of Central Tendency
- Median
- Null Hypothesis
- Pie Chart
- Regression
- Standard Deviation
- Statistic
- Causal Modeling
- Discourse/Conversation Analysis
- Econometrics
- Epistemology
- Ethnography
- Evaluation
- Event History Analysis
- Experimental Design
- Factor Analysis and Related Techniques
- Feminist Methodology
- Generalized Linear Models
- Historical/Comparative
- Interviewing in Qualitative Research
- Latent Variable Model
- Life History/Biography
- Log-Linear Models (Categorical Dependent Variables)
- Longitudinal Analysis
- Mathematics and Formal Models
- Measurement Level
- Measurement Testing and Classification
- Multilevel Analysis
- Multiple Regression
- Qualitative Data Analysis
- Sampling in Qualitative Research
- Sampling in Surveys
- Scaling
- Significance Testing
- Simple Regression
- Survey Design
- Time Series
- ARIMA
- Box-Jenkins Modeling
- Cointegration
- Detrending
- Durbin-Watson Statistic
- Error Correction Models
- Forecasting
- Granger Causality
- Interrupted Time-Series Design
- Intervention Analysis
- Lag Structure
- Moving Average
- Periodicity
- Serial Correlation
- Spectral Analysis
- Time-Series Cross-Section (TSCS) Models
- Time-Series Data (Analysis/Design)
- Trend Analysis
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches