Entry
Reader's guide
Entries A-Z
Subject index
Asymmetric Measures
Association coefficients measure the strength of the relation between two variables X and Y and, for ordinal and quantitative (interval and ratio-scaled) variables, the direction of the association. Asymmetric (or directional) association coefficients also assume that one of the two variables (e.g., X) can be identified as the independent variable and the other variable (e.g., Y) as the dependent variable.
As an example, in a survey of university graduates, the variable X might be gender (nominal, dichotomous), ethnic group (nominal), the socioeconomic status of parents (ordinal), or the income of parents (quantitative). The variable Y might be the field of study or party affiliation (nominal), a grade (ordinal), the income of respondents (quantitative), or membership in a union (nominal, dichotomous, with a “yes” or “no” response category).
Available Coefficients
Most statistical software packages, such as SPSS, offer asymmetric coefficients only for special combinations of measurement levels. These coefficients are described first.
Measures for Nominal-Nominal Tables
Measures for nominal variables are lambda (λ), Goodman and Kruskal's tau (τ), and the uncertainty coefficient U. All measures are based on the definition of PROPORTIONAL REDUCTION OF ERROR (PRE):
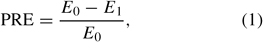
where E0 is the error in the dependent variable Y without using the independent variable X to predict or explain Y, and E1 is the error in Y if X is used to predict or explain Y.
Both τ and U use definitions of variance to compute E0 and E1. Similar to the well-known eta (η) from the ANALYSIS OF VARIANCE (see below), E0 is the total variance of Y, and E1 is the residual variance (variance within the categories of X). For τ, the so-called Gini concentration is used to measure the variation (Agresti, 1990, pp. 24–25), and U applies the concept of entropy. For λ, a different definition is used: It analyzes to what extent the dependent variable can be predicted both without knowing X and with knowledge of X.
All three coefficients vary between 0 (no reduction in error) and 1 (perfect reduction in error). Even if a clear association exists, λ may be zero or near zero. This is the case if one category of the dependent variable is dominant, so that the same category of Y has the highest frequencies and becomes the best predictor within each condition X.
Measure for Ordinal-Ordinal Tables
The most prominent measure for this pattern is Somers' d. Somers' d is defined as the least squares regression slope (dy/x = sxy/s2x) between the dependent variable Y and the independent variable X, if both variables are treated as ordinal (Agresti, 1984, pp. 161–163), and Daniels' formula for generalized correlation coefficient (see Association) is used to compute the variance s2x of X and the covariance sxy between X and Y. Somers' d is not a PRE coefficient. The corresponding PRE coefficient is the symmetric Kendall's τ2b, which can be interpreted as explained variance and is equal to the geometric mean if Somers' d is computed for X and Y as dependent variables (= dy/x and dx/y). If both variables are dichotomous, Somers' d is equal to the difference of proportions (Agresti, 1984, p. 161).
...
- Analysis of Variance
- Association and Correlation
- Association
- Association Model
- Asymmetric Measures
- Biserial Correlation
- Canonical Correlation Analysis
- Correlation
- Correspondence Analysis
- Intraclass Correlation
- Multiple Correlation
- Part Correlation
- Partial Correlation
- Pearson's Correlation Coefficient
- Semipartial Correlation
- Simple Correlation (Regression)
- Spearman Correlation Coefficient
- Strength of Association
- Symmetric Measures
- Basic Qualitative Research
- Basic Statistics
- F Ratio
- N(n)
- t-Test
- X¯
- Y Variable
- z-Test
- Alternative Hypothesis
- Average
- Bar Graph
- Bell-Shaped Curve
- Bimodal
- Case
- Causal Modeling
- Cell
- Covariance
- Cumulative Frequency Polygon
- Data
- Dependent Variable
- Dispersion
- Exploratory Data Analysis
- Frequency Distribution
- Histogram
- Hypothesis
- Independent Variable
- Measures of Central Tendency
- Median
- Null Hypothesis
- Pie Chart
- Regression
- Standard Deviation
- Statistic
- Causal Modeling
- Discourse/Conversation Analysis
- Econometrics
- Epistemology
- Ethnography
- Evaluation
- Event History Analysis
- Experimental Design
- Factor Analysis and Related Techniques
- Feminist Methodology
- Generalized Linear Models
- Historical/Comparative
- Interviewing in Qualitative Research
- Latent Variable Model
- Life History/Biography
- Log-Linear Models (Categorical Dependent Variables)
- Longitudinal Analysis
- Mathematics and Formal Models
- Measurement Level
- Measurement Testing and Classification
- Multilevel Analysis
- Multiple Regression
- Qualitative Data Analysis
- Sampling in Qualitative Research
- Sampling in Surveys
- Scaling
- Significance Testing
- Simple Regression
- Survey Design
- Time Series
- ARIMA
- Box-Jenkins Modeling
- Cointegration
- Detrending
- Durbin-Watson Statistic
- Error Correction Models
- Forecasting
- Granger Causality
- Interrupted Time-Series Design
- Intervention Analysis
- Lag Structure
- Moving Average
- Periodicity
- Serial Correlation
- Spectral Analysis
- Time-Series Cross-Section (TSCS) Models
- Time-Series Data (Analysis/Design)
- Trend Analysis
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches