Entry
Reader's guide
Entries A-Z
Subject index
General Linear Model
The general linear model (GLM) provides a general framework for a large set of models whose common goal is to explain or predict a quantitative dependent variable by a set of independent variables that can be categorical or quantitative. The GLM encompasses techniques such as Student's t test, simple and multiple linear regression, analysis of variance, and covariance analysis. The GLM is adequate only for fixed-effect models. In order to take into account random-effect models, the GLM needs to be extended and becomes the mixed-effect model.
Notations
Vectors are denoted with boldface lower-case letters (e.g., y), and matrices are denoted with boldface upper-case letters (e.g., X). The transpose of a matrix is denoted by the superscript, and the inverse of a matrix is denoted by the superscript 1. There are I observations. The values of a quantitative dependent variable describing the I observations are stored in an I by 1 vector denoted y. The values of the independent variables describing the I observations are stored in an I by K matrix denoted X. K is smaller than I, and X is assumed to have rank K (i.e., X is full rank on its columns). A quantitative independent variable can be directly stored in X, but a qualitative independent variable needs to be recoded with as many columns as there are degrees of freedom for this variable. Common coding schemes include dummy coding, effect coding, and contrast coding.
Core Equation
For the GLM, the values of the dependent variable are obtained as a linear combination of the values of the independent variables. The vectors for the coefficients of the linear combination are stored in a K by 1 vector denoted b. In general, the values of y cannot be perfectly obtained by a linear combination of the columns of X, and the difference between the actual and the predicted values is called the prediction error. The values of the error are stored in an I by 1 vector denoted e. Formally, the GLM is stated as

The predicted values are stored in an I by 1 vector denoted ŷ, and therefore, Equation 1 can be rewritten as
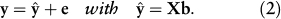
Putting together Equations 1 and 2 shows that

Additional Assumptions
The independent variables are assumed to be fixed variables (i.e., their values will not change for a replication of the experiment analyzed by the GLM, and they are measured without error). The error is interpreted as a random variable; in addition, the I components of the error are assumed to be independently and identically distributed (i.i.d.), and their distribution is assumed to be a normal distribution with a zero mean and a variance denoted σ2e. The values of the dependent variable are assumed to be a random sample of a population of interest. Within this framework, the vector b is seen as an estimation of the population parameter vector β.
Least Square Estimate
Under the assumptions of the GLM, the population parameter vector β is estimated by b, which is computed as
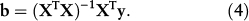
This value of b minimizes the residual sum of squares (i.e., b is such that eTe is minimum).
...
- Descriptive Statistics
- Distributions
- Graphical Displays of Data
- Hypothesis Testing
- Alternative Hypotheses
- Beta
- Critical Value
- Decision Rule
- Hypothesis
- Nondirectional Hypotheses
- Nonsignificance
- Null Hypothesis
- One-Tailed Test
- p Value
- Power
- Power Analysis
- Significance Level, Concept of
- Significance Level, Interpretation and Construction
- Significance, Statistical
- Two-Tailed Test
- Type I Error
- Type II Error
- Type III Error
- Important Publications
- “Coefficient Alpha and the Internal Structure of Tests”
- “Convergent and Discriminant Validation by the Multitrait-Multimethod Matrix”
- “Meta-Analysis of Psychotherapy Outcome Studies”
- “On the Theory of Scales of Measurement”
- “Probable Error of a Mean, The”
- “Psychometric Experiments”
- “Sequential Tests of Statistical Hypotheses”
- “Technique for the Measurement of Attitudes, A”
- “Validity”
- Aptitudes and Instructional Methods
- Doctrine of Chances, The
- Logic of Scientific Discovery, The
- Nonparametric Statistics for the Behavioral Sciences
- Probabilistic Models for Some Intelligence and Attainment Tests
- Statistical Power Analysis for the Behavioral Sciences
- Teoria Statistica Delle Classi e Calcolo Delle Probabilità
- Inferential Statistics
- Association, Measures of
- Coefficient of Concordance
- Coefficient of Variation
- Coefficients of Correlation, Alienation, and Determination
- Confidence Intervals
- Margin of Error
- Nonparametric Statistics
- Odds Ratio
- Parameters
- Parametric Statistics
- Partial Correlation
- Pearson Product-Moment Correlation Coefficient
- Polychoric Correlation Coefficient
- Q-Statistic
- R2
- Randomization Tests
- Regression Coefficient
- Semipartial Correlation Coefficient
- Spearman Rank Order Correlation
- Standard Error of Estimate
- Standard Error of the Mean
- Student's t Test
- Unbiased Estimator
- Weights
- Item Response Theory
- Mathematical Concepts
- Measurement Concepts
- Organizations
- Publishing
- Qualitative Research
- Reliability of Scores
- Research Design Concepts
- Aptitude-Treatment Interaction
- Cause and Effect
- Concomitant Variable
- Confounding
- Control Group
- Interaction
- Internet-Based Research Method
- Intervention
- Matching
- Natural Experiments
- Network Analysis
- Placebo
- Replication
- Research
- Research Design Principles
- Treatment(s)
- Triangulation
- Unit of Analysis
- Yoked Control Procedure
- Research Designs
- A Priori Monte Carlo Simulation
- Action Research
- Adaptive Designs in Clinical Trials
- Applied Research
- Behavior Analysis Design
- Block Design
- Case-Only Design
- Causal-Comparative Design
- Cohort Design
- Completely Randomized Design
- Cross-Sectional Design
- Crossover Design
- Double-Blind Procedure
- Ex Post Facto Study
- Experimental Design
- Factorial Design
- Field Study
- Group-Sequential Designs in Clinical Trials
- Laboratory Experiments
- Latin Square Design
- Longitudinal Design
- Meta-Analysis
- Mixed Methods Design
- Mixed Model Design
- Monte Carlo Simulation
- Nested Factor Design
- Nonexperimental Design
- Observational Research
- Panel Design
- Partially Randomized Preference Trial Design
- Pilot Study
- Pragmatic Study
- Pre-Experimental Designs
- Pretest-Posttest Design
- Prospective Study
- Quantitative Research
- Quasi-Experimental Design
- Randomized Block Design
- Repeated Measures Design
- Response Surface Design
- Retrospective Study
- Sequential Design
- Single-Blind Study
- Single-Subject Design
- Split-Plot Factorial Design
- Thought Experiments
- Time Studies
- Time-Lag Study
- Time-Series Study
- Triple-Blind Study
- True Experimental Design
- Wennberg Design
- Within-Subjects Design
- Zelen's Randomized Consent Design
- Research Ethics
- Research Process
- Clinical Significance
- Clinical Trial
- Cross-Validation
- Data Cleaning
- Delphi Technique
- Evidence-Based Decision Making
- Exploratory Data Analysis
- Follow-Up
- Inference: Deductive and Inductive
- Last Observation Carried Forward
- Planning Research
- Primary Data Source
- Protocol
- Q Methodology
- Research Hypothesis
- Research Question
- Scientific Method
- Secondary Data Source
- Standardization
- Statistical Control
- Type III Error
- Wave
- Research Validity Issues
- Bias
- Critical Thinking
- Ecological Validity
- Experimenter Expectancy Effect
- External Validity
- File Drawer Problem
- Hawthorne Effect
- Heisenberg Effect
- Internal Validity
- John Henry Effect
- Mortality
- Multiple Treatment Interference
- Multivalued Treatment Effects
- Nonclassical Experimenter Effects
- Order Effects
- Placebo Effect
- Pretest Sensitization
- Random Assignment
- Reactive Arrangements
- Regression to the Mean
- Selection
- Sequence Effects
- Threats to Validity
- Validity of Research Conclusions
- Volunteer Bias
- White Noise
- Sampling
- Cluster Sampling
- Convenience Sampling
- Demographics
- Error
- Exclusion Criteria
- Experience Sampling Method
- Nonprobability Sampling
- Population
- Probability Sampling
- Proportional Sampling
- Quota Sampling
- Random Sampling
- Random Selection
- Sample
- Sample Size
- Sample Size Planning
- Sampling
- Sampling and Retention of Underrepresented Groups
- Sampling Error
- Stratified Sampling
- Systematic Sampling
- Scaling
- Software Applications
- Statistical Assumptions
- Statistical Concepts
- Autocorrelation
- Biased Estimator
- Cohen's Kappa
- Collinearity
- Correlation
- Criterion Problem
- Critical Difference
- Data Mining
- Data Snooping
- Degrees of Freedom
- Directional Hypothesis
- Disturbance Terms
- Error Rates
- Expected Value
- Fixed-Effects Models
- Inclusion Criteria
- Influence Statistics
- Influential Data Points
- Intraclass Correlation
- Latent Variable
- Likelihood Ratio Statistic
- Loglinear Models
- Main Effects
- Markov Chains
- Method Variance
- Mixed- and Random-Effects Models
- Models
- Multilevel Modeling
- Odds
- Omega Squared
- Orthogonal Comparisons
- Outlier
- Overfitting
- Pooled Variance
- Precision
- Quality Effects Model
- Random-Effects Models
- Regression Artifacts
- Regression Discontinuity
- Residuals
- Restriction of Range
- Robust
- Root Mean Square Error
- Rosenthal Effect
- Serial Correlation
- Shrinkage
- Simple Main Effects
- Simpson's Paradox
- Sums of Squares
- Statistical Procedures
- Accuracy in Parameter Estimation
- Analysis of Covariance (ANCOVA)
- Analysis of Variance (ANOVA)
- Barycentric Discriminant Analysis
- Bivariate Regression
- Bonferroni Procedure
- Bootstrapping
- Canonical Correlation Analysis
- Categorical Data Analysis
- Confirmatory Factor Analysis
- Contrast Analysis
- Descriptive Discriminant Analysis
- Discriminant Analysis
- Dummy Coding
- Effect Coding
- Estimation
- Exploratory Factor Analysis
- Greenhouse-Geisser Correction
- Hierarchical Linear Modeling
- Holm's Sequential Bonferroni Procedure
- Jackknife
- Latent Growth Modeling
- Least Squares, Methods of
- Logistic Regression
- Mean Comparisons
- Missing Data, Imputation of
- Multiple Regression
- Multivariate Analysis of Variance (MANOVA)
- Pairwise Comparisons
- Path Analysis
- Post Hoc Analysis
- Post Hoc Comparisons
- Principal Components Analysis
- Propensity Score Analysis
- Sequential Analysis
- Stepwise Regression
- Structural Equation Modeling
- Survival Analysis
- Trend Analysis
- Yates's Correction
- Statistical Tests
- Bartlett's Test
- Behrens-Fisher t′ Statistic
- Chi-Square Test
- Duncan's Multiple Range Test
- Dunnett's Test
- F Test
- Fisher's Least Significant Difference Test
- Friedman Test
- Honestly Significant Difference (HSD) Test
- Kolmogorov-Smirnov Test
- Kruskal-Wallis Test
- Mann-Whitney U Test
- Mauchly Test
- McNemar's Test
- Multiple Comparison Tests
- Newman-Keuls Test and Tukey Test
- Omnibus Tests
- Scheffé Test
- Sign Test
- t Test, Independent Samples
- t Test, One Sample
- t Test, Paired Samples
- Tukey's Honestly Significant Difference (HSD)
- Welch's t Test
- Wilcoxon Rank Sum Test
- z Test
- Theories, Laws, and Principles
- Bayes's Theorem
- Central Limit Theorem
- Classical Test Theory
- Correspondence Principle
- Critical Theory
- Falsifiability
- Game Theory
- Gauss-Markov Theorem
- Generalizability Theory
- Grounded Theory
- Item Response Theory
- Occam's Razor
- Paradigm
- Positivism
- Probability, Laws of
- Theory
- Theory of Attitude Measurement
- Weber-Fechner Law
- Types of Variables
- Validity of Scores
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches