Entry
Reader's guide
Entries A-Z
Subject index
Power Laws
A power law is a statistical relationship in which the probability of observing a particular “size” of some event is inversely proportional to some power (exponent) of that size. Let y be the size of the event—say the Richter measurement of an earthquake, or the number of acres destroyed in a forest fire—then
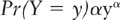
and
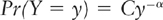
where C is a constant and α is the power law exponent. This relationship is scale invariant in the sense that the same α and C describe the probability of a particular magnitude of event no matter how large or small the size in question. Hence notice that, if Y is power law distributed, large events will tend to be relatively rare, while small-sized events will be relatively common. A feature of power laws is that
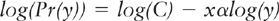
in which case a (log-log) plot of log(Pr(y)) versus log(y) will be a straight line. Consider Figure 1; here, some simulated power law data are displayed for which it is (approximately) true that Pr(y) = 0.5xy−2.5. That is, C = 0.5 and α = −2.5. In Figure 2 we take logs of both axes and then impose a linear regression line. The correlation between the two (logged) variables (the R2 for the regression) is typically very high, and is 0.945 here.
Power laws are regularly seen in the physical sciences where there are a wide variety of extremely diverse examples, some of which have particular names; for example, the Stefan-Boltzmann law concerns energy radiation, and the inverse square law describes the gravitational pull between objects. Such laws are fairly rare, and rarely discussed, in the social sciences. Power laws are seen in complex system models, which are used to describe complicated networks of some kind. Examples include the U.S. power grid, a beehive, and an advanced industrial economy. The individual elements of these networks—like bee-to-bee interaction—may be impossible to measure and observe directly, so system-level observations are the norm. Successfully asserting power law behavior for a particular system requires a large amount of data (typically hundreds of observations) with a wide variance (from very small magnitudes to huge ones) and the careful ruling out of other possible density functions such as the lognormal and various versions of the exponential function. The estimation of α is usually performed via maximum likelihood with goodness of fit to the power law distribution verified with a Kolmogorov-Smirnov test.
A classic example discussed in political science was given by Fry Richardson, a mathematician active in the postwar period. Richardson considered international and domestic cases of “deadly quarrels” (wars, murders, etc.). Using a logarithmic scale with categories of 3, 4, 5, 6, and 7, he classified the various events by their casualty numbers. So, for example, World War II with over a million casualties was placed (with the Great War) into the 7 bin. He discovered a remarkable regularity: for every tenfold increase in the size of the event—for example, a move from bin 3 to bin 4, or from bin 6 to bin 7—the number of such events decreased by around 2.5 times relative to the previous category. This result, with α = − 2.5, has proved stable in the face of new data, and has been extended to the study of terrorist acts.
...
- Adler, Alfred
- Adorno, Theodor
- Althusser, Louis
- Arendt, Hannah
- Aristotle
- Bachrach, Peter, and Baratz, Morton
- Bakunin, Mikhail
- Barry, Brian
- Bourdieu, Pierre
- Bull, Hedley
- Carr, E. H.
- Cartwright, Dorwin
- Castells, Manuel
- Clausewitz, Carl von
- Clegg, Stewart
- Coleman, James S.
- Cox, Robert W.
- Dahl, Robert A.
- Deutsch, Karl
- Domhoff, G. William
- Dowding, Keith
- Eagly, Alice
- Felsenthal, Dan S.
- Fiske, Susan
- Flyvbjerg, Bent
- Foucault, Michel
- French, John R. P., Jr.
- Giddens, Anthony
- Gramsci, Antonio
- Granovetter, Mark
- Habermas, Jürgen
- Hall, Judith A.
- Harsanyi, John C.
- Haugaard, Mark
- Hobbes, Thomas
- Holler, Manfred
- Hunter, Floyd
- Jessop, Bob
- Jost, John
- Kropotkin, Peter
- Laclau, Ernesto, and Mouffe, Chantal
- Lasswell, Harold
- Lewin, Kurt, and Power
- Luhmann, Niklas
- Lukes, Steven
- Machiavelli, Niccolò
- Machover, Moshé
- Mann, Michael
- Marx, Karl
- McClelland, David
- Michels, Robert
- Miliband, Ralph
- Mills, C. Wright
- Morgenthau, Hans J.
- Morriss, Peter
- Nietzsche, Friedrich
- Parsons, Talcott
- Poulantzas, Nicos
- Raven, Bertram
- Riker, William H.
- Sabatier, Paul
- Scott, James
- Spence, Janet
- Sprout, Harold
- Waltz, Kenneth
- Weber, Max
- Wight, Martin
- Wolfers, Arnold
- Wright, Quincy
- Ability
- Ableness
- Absolutism
- Adverse Selection
- Agency
- Agenda Power
- Agenda Setters
- Argument, Power of
- Authority
- Autonomy
- Bargaining
- Blackmail
- Bureaucratic Power
- Cabal
- Capability
- Capital, Marxist
- Causation
- Coercion, Analytic
- Coercion and Power
- Collective Action Problem
- Complex Equality (Walzer)
- Consent
- Control
- Cooperation
- Coordination
- Corruption
- Decentering (of Subject, of Structure)
- Deflected Wants
- Deliberation
- Determinacy
- Determinism
- Discipline
- Discourse
- Dispositif
- Domain
- Domination
- Entrepreneurs
- Exclusion
- Exercise Fallacy
- Exit and Voice as Forms of Power
- Expectancy Confirmation, Power and
- Exploitation
- Fair Division
- False Consciousness
- Fear, Use of
- Female Leadership Among Mammals
- Free Market
- Free Will
- Freedom
- Governmentality
- Habitus
- Hegemony
- Hierarchy
- Ideas
- Ideology
- Influence
- Interests
- Invisible Hand
- Leadership
- Legitimation
- Loyalty
- Luck
- Luck, Brute
- Manipulation
- Mechanisms
- Mobilization of Bias
- Moral Hazard
- Networks and Communities
- Nonverbal Communication and Power
- Opportunity
- Perceptual Symbols of Power
- Persuasion
- Pluralism
- Policy Entrepreneurs
- Political Thinking as Power
- Power Elite
- Power Motive
- Propaganda
- Public Goods
- Racism, Role of Power in
- Rationality
- Relative Autonomy of the State
- Responsibility
- Rhetoric
- Scope
- Second Face
- Social Capital
- Submissive
- Subordination
- Systematic Luck
- Systemic Power
- Third Face
- Threats
- Throffers
- Trade
- Trust
- Unintended Consequences
- Vehicle Fallacy
- Will to Power
- Agenda Power
- Agenda Setters
- Banzhaf Value
- Banzhaf Voting Power Measure
- Bargaining
- Blocking Coalition
- Bribe Index
- Chicken Games
- Coalition Theory
- Coleman, James S.
- Coleman Index
- Computer Algorithms for Power Indices
- Core of a Game
- Dowding, Keith
- Fair Division
- Felsenthal, Dan S.
- Game Forms, Power in
- Game-Theoretical Approaches to Power
- Grand Coalition
- Gunboat Diplomacy
- Harsanyi, John C.
- Holler, Manfred
- Homogeneous Weighted Majority Games
- I-Power
- Jurisdictions and Structure-Induced Equilibria
- Machover, Moshé
- Martin Index
- Minimal Winning Coalition
- Mutually Assured Destruction
- Non Decision Making
- Noncooperative Games
- Owen Value
- Paradox of New Members
- Parties, Policy-Seeking Versus Power-Seeking
- Penrose Voting Power Measure
- Pivot Player
- Power Indices
- Power Laws
- Power to Initiate Action and Power to Prevent Action
- P-Power
- Preference Versus Nonpreference-Based Concepts
- Proper Simple Game
- Public Goods Index
- Qualified Majority Voting
- Quarreling Paradox
- Shapley Value
- Shapley—Shubik Index
- Shareholder Voting Power
- Simple Games
- Small Worlds, Power in
- Spatial Voting Analysis
- Square Root Rules
- Strategic Power Index
- Tijs Value
- U.S. Electoral College, Power in
- Value of a Game
- Variable-Sum Games
- Veto Players
- Veto Power
- Voting Paradoxes
- Voting Power
- Weighted Majority Game
- Weighted Voting
- Agenda Power
- Agenda Setters
- Bicameral Legislature
- Budget-Maximizing Bureaucrats
- Bureaucratic Power
- Capture Theory of Regulation
- Central Intelligence Agency
- Corporatism
- Dominant Parties
- e-Governance
- Elections
- Federal Structure
- Internet and Power
- Leadership
- Media, The
- Organization of the State
- Political Parties
- Prime Ministerial and Presidential
- Principal-Agent Relationship
- Prisoner's Dilemma
- Referendums
- Structure-Induced Equilibrium
- Unicameral Legislature
- U.S. Electoral College, Power in
- Alliances
- Anarchy in International Relations
- Appeasement
- Arms Race
- Balance of Power
- Banks
- Bargaining in International Relations
- Bull, Hedley
- Carr, E. H.
- Cartwright, Dorwin
- Chicken Games
- Civil War
- Clausewitz, Carl von
- Compliance (International)
- Constructivist View of Power in International Relations
- Conventional Deterrence
- Cox, Robert W.
- Cuban Missile Crisis
- Defensive Realism
- Dependency Theory in International Relations
- Deterrence Theory
- Deterrent Threats
- Deutsch, Karl
- Diplomacy
- Empire
- Environmental Treaties
- Espionage
- Executive Power
- Extended Deterrence
- Feminist International Relations, View of Power
- First-Strike Capability
- Gunboat Diplomacy
- Hegemonic Power
- Hegemonic War
- Hegemony
- Idealism in International Relations
- Imperial Power
- Imperialism
- Intelligence
- Lasswell, Harold
- League of Nations
- Military in Government
- Morgenthau, Hans J.
- Multinational Corporations
- Mutually Assured Destruction
- Neoliberalism
- Neorealism
- Offense/Defense Dominance
- Postmodernist View of Power in International Relations
- Power Transition Theory
- Realism in International Relations
- Regime Theory in International Relations
- Sea Power
- Security
- Security Dilemma
- Separation of Powers
- Sovereignty
- Spiral Model
- Sprout, Harold
- Strategic Interaction in International Relations
- Terror Regimes
- Terrorism
- Waltz, Kenneth
- War
- Wight, Martin
- Wolfers, Arnold
- Wright, Quincy
- Agency-Structure Problem
- Authority
- Caste System (India)
- Chicken Games
- Deliberative Democracy
- Gender, Role of Power in
- Heterosexism, Role of Power in
- Hierarchy
- Interdependence Theory
- Leadership and Gender
- Power as Control Theory
- Psychological Empowerment
- Submissive
- Veiled Women
- Agency
- Agency-Structure Problem
- Autonomy
- Bases of Power
- Free Will
- Gender, Role of Power in
- Interdependence Theory
- Leadership and Gender
- Psychological Empowerment
- Submissive
- Agency-Structure Problem
- Bachrach, Peter, and Baratz, Morton
- Barry, Brian
- Bourdieu, Pierre
- Community Power Debate
- Consensual Power, Theories of
- Critical Theory
- Dahl, Robert A.
- Defensive Realism
- Deliberative Democracy
- Dependency Theory in International Relations
- Discourse
- Domhoff, G. William
- Domination
- Dowding, Keith
- Elite Theories
- Essentially Contested Concept
- Free Will
- Freedom
- Global Governance
- Hunter, Floyd
- Liberalism
- Luck
- Miliband, Ralph
- Miliband-Poulantzas Debate
- Mills, C. Wright
- Mobilization of Bias
- Neoliberalism
- Neorealism
- Non Decision Making
- Organization of the State
- Pluralism
- Postmodernist View of Power in International Relations
- Poulantzas, Nicos
- Power as Control Theory
- Power Elite
- Power To and Power Over
- Psychological Empowerment
- Queer Theories of Power
- Rationality
- Realism in International Relations
- Regime Theory in International Relations
- Regime Theory in Urban Politics
- Relative Autonomy of the State
- Resources as Measuring Power
- Second Face
- Social Dominance Theory
- Spiral Model
- Structural Power
- Structural Suggestion
- Structuration
- Three Faces of Power
- Transactional and Transformational Leadership
- Adverse Selection
- Agency-Structure Problem
- Community Power Debate
- Essentially Contested Concept
- Exercise Fallacy
- False Consciousness
- Fungibility of Power Resources
- Mechanisms
- Pluralism
- Power Elite
- Power Laws
- Preference Versus Nonpreference-Based Concepts
- Principal-Agent Relationship
- Rationality
- Realism in International Relations
- Realist Accounts of Power
- Reputational Analysis
- Resources as Measuring Power
- Systematic Luck
- Third Face
- Three Faces of Power
- Agenda Power
- Agenda Setters
- Authority
- Banzhaf Value
- Bicameral Legislature
- Budget-Maximizing Bureaucrats
- Bureaucratic Power
- Business and Power
- Capital, Marxist
- Capital, Neoclassical
- Capture Theory of Regulation
- Central Intelligence Agency
- Civil War
- Coalition Theory
- Collective Action Problem
- Community Power Debate
- Core Parties
- Corporatism
- Coup d'État
- Dahl, Robert A.
- Democracy
- Dictatorship
- Dominant Parties
- Dowding, Keith
- e-Governance
- Elections
- Executive Power
- Fascism
- Federal Structure
- Global Governance
- Globalization
- Governmentality
- Grand Coalition
- Growth Coalitions
- Heresthetics
- Hierarchy
- Hunter, Floyd
- Intelligence
- Internet and Power
- Jursidictions and Structure-Induced Equilibria
- Lasswell, Harold
- Leadership
- Legislative Power
- Liberalism
- Lukes, Steven
- Martin Index
- McClelland, David
- Michels, Robert
- Military in Government
- Mills, C. Wright
- Minimal Winning Coalition
- Morriss, Peter
- Nationalism
- Organization of the State
- Parties, Policy-Seeking Versus Power-Seeking
- Parties, Strong and Very Strong
- Pivotal Politics
- Pluralism
- Police State
- Policy Entrepreneurs
- Political Parties
- Post-Fordism
- Power Elite
- Power To and Power Over
- Prime Ministerial and Presidential
- Principal-Agent Relationship
- Realist Accounts of Power
- Referendums
- Relative Autonomy of the State
- Revolution
- Revolutionary Cell Structure
- Right-Wing Authoritarianism
- Riker, William H.
- Riots
- Second Face
- Social Capital
- Social Power
- Spatial Voting Analysis
- Structural Power
- Structural Suggestion
- Structure-Induced Equilibrium
- Terror Regimes
- Terrorism
- Testosterone, Power and
- Totalitarianism
- Unicameral Legislature
- U.S. Electoral College, Power in
- Veiled Women
- Veto Players
- Vote-Maximizing Parties
- Voting
- Voting Paradoxes
- Voting Power
- Weber, Max
- Weighted Voting
- Women as Political Leaders
- Agency-Structure Problem
- Anarchism, Power in
- Authority
- Barry, Brian
- Bourdieu, Pierre
- Capital, Marxist
- Capital, Neoclassical
- Castells, Manuel
- Deliberative Democracy
- Democracy
- Dispositif
- Distributive Justice
- Domhoff, G. William
- Dowding, Keith
- Freedom
- Global Governance
- Globalization
- Governmentality
- Gramsci, Antonio
- Habermas, Jürgen
- Hobbes, Thomas
- Hunter, Floyd
- Jessop, Bob
- Justice
- Liberalism
- Lukes, Steven
- Machiavelli, Niccolò
- Marx, Karl
- Michels, Robert
- Miliband, Ralph
- Mills, C. Wright
- Morriss, Peter
- Nationalism
- Nietzsche, Friedrich
- Paternalism
- Pluralism
- Political Legitimacy
- Post-Fordism
- Poulantzas, Nicos
- Power Elite
- Power To and Power Over
- Power With
- Sabatier, Paul
- Scott, James
- Second Face
- Social Capital
- Social Power
- Sovereignty
- Structural Power
- Structural Suggestion
- Will to Power
- Adler, Alfred
- Authoritarian Personality
- Bases of Power
- Deflected Wants
- Eagly, Alice
- Expectancy Confirmation, Power and
- Fiske, Susan
- Framing
- French, John R. P., Jr.
- Granovetter, Mark
- Groupthink
- Hall, Judith A.
- Human Dominance Motivation
- Interdependence Theory
- Jost, John
- Laclau, Ernesto, and Mouffe, Chantal
- Lewin, Kurt, and Power
- Power, Cognition, and Behavior
- Power as Control Theory
- Power Motive
- Psychological Empowerment
- Rationality
- Raven, Bertram
- Social Dominance Theory
- Status
- Striving for Superiority
- System Justification Theory
- Transactional and Transformational Leadership
- Agency
- Agency-Structure Problem
- Biopower
- Caste System (India)
- Clegg, Stewart
- Decentering (of Subject, of Structure)
- Deliberation
- Flyvbjerg, Bent
- Foucault, Michel
- Free Will
- Giddens, Anthony
- Governmentality
- Groupthink
- Habermas, Jürgen
- Habitus
- Haugaard, Mark
- Jessop, Bob
- Luhmann, Niklas
- Lukes, Steven
- Mann, Michael
- Michels, Robert
- Miliband, Ralph
- Mills, C. Wright
- Morriss, Peter
- Nationalism
- Parsons, Talcott
- Perceptual Symbols of Power
- Post-Fordism
- Propaganda
- Rationality
- Realist Accounts of Power
- Revolution
- Rhetoric
- Right-Wing Authoritarianism
- Scott, James
- Second Face
- Small Worlds, Power in
- Social Breakdown
- Social Capital
- Substructure and Superstructure
- Status
- Strength of Weak Ties
- Structural Power
- Structural Suggestion
- Structuration
- Trust
- Veiled Women
- Weber, Max
- Will to Power
- Animal Groups, Power in
- Causal Theories of Power
- Coercion and Power
- Collective Action Problem
- Community Power Debate
- Elite Theories
- Exchange Theory
- Feminist International Relations, View of Power
- Feminist Theories of Power
- Marxist Accounts of Power
- Neoliberalism
- Neorealism
- Post-Fordism
- Postmodernist View of Power in International Relations
- Power as Control Theory
- Power To and Power Over
- Queer Theories of Power
- Realism in International Relations
- Realist Accounts of Power
- Relational Power
- Social Power
- Striving for Superiority
- System Justification Theory
- Third Face
- Three Faces of Power
- Animal Groups, Power in
- Consensual Power, Theories of
- Constructivist View of Power in International Relations
- Critical Theory
- Defensive Realism
- Deterrence Theory
- Elite Theories
- Exercise Fallacy
- Exploitation
- False Consciousness
- Female Leadership Among Mammals
- Fungibility of Power Resources
- Hegemonic Power
- Hegemony
- Heterosexism, Role of Power in
- Human Dominance Motivation
- Ideology
- Imperial Power
- Influence
- Invisible Hand
- Knowledge and Power
- Language and Power
- Legislative Power
- Manipulation
- Media, The
- Military in Government
- Mobilization of Bias
- Monopoly Power
- Networks, Power in
- Networks and Communities
- Nonverbal Communication and Power
- Perceptual Symbols of Power
- Persuasion
- Pluralism
- Police State
- Political Thinking as Power
- Power, Cognition, and Behavior
- Power as Control Theory
- Power Motive
- Power To and Power Over
- Power Transition Theory
- Power With
- Prime Ministerial and Presidential
- Propaganda
- Psychological Empowerment
- Regime Theory in International Relations
- Relational Power
- Relative Autonomy of the State
- Religious Power
- Revolutionary Cell Structure
- Rhetoric
- Sea Power
- Second Face
- Sexism, Role of Power in
- Social Capital
- Social Dominance Theory
- Social Power
- Striving for Superiority
- Symbolic Power and Violence
- Systematic Luck
- Systemic Power
- Terrorism
- Testosterone, Power and
- Third Face
- Threats
- Three Faces of Power
- Throffers
- Transactional and Transformational Leadership
- Will to Power
- Bachrach, Peter, and Baratz, Morton
- Castells, Manuel
- Community Power Debate
- Dahl, Robert A.
- Domhoff, G. William
- Dowding, Keith
- Elite Theories
- Flyvbjerg, Bent
- Growth Coalitions
- Hunter, Floyd
- Lukes, Steven
- Mobilization of Bias
- Non Decision Making
- Pluralism
- Post-Fordism
- Power Elite
- Regime Theory in Urban Politics
- Sabatier, Paul
- Systematic Luck
- Systemic Power
- Third Face
- Three Faces of Power
- World Cities
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches