Entry
Reader's guide
Entries A-Z
Subject index
Confidence Intervals/Hypothesis Testing/Effect Sizes
Inferential statistics play a critical role in assessing whether training, tests, or other organizational interventions have an effect that can be reliably expected based on data collected from samples of organizational members. For example, the score from a selection test administered to a sample of 100 job applicants could be correlated with the test takers' subsequent performance ratings to determine how well the test predicts job performance. If we find that the correlation (r) calculated from the sample's test scores and ratings is .25, we are left with several questions: How does a sample-derived correlation of .25 compare with the correlation that could be obtained if we had test and ratings data on all cases in the population? How likely is it that we will get the same or approximately the same value for r with another sample of 100 cases? How good is an r of .25? Confidence intervals, significance testing, and effect sizes play pivotal roles in answering these questions.
Confidence Intervals
Using the foregoing example, assume that the correlation (ρ) between the test scores and ratings is .35 in the population. This ρ of .35 is called a parameter because it is based on a population, whereas the r of .25 is called a statistic because it is based on a sample. If another sample of 100 cases were drawn randomly from the same population with an infinite number of cases, the r calculated using test and ratings data from the new sample would probably differ from both the ρ of .35 and the r of .25 calculated for the first sample. We can continue sampling and calculating r an infinite number of times, and each rs would be an estimate of ρ. Typically, r would be distributed around ρ, with some being smaller than .35 and others being larger. If the mean of all possible rs equals ρ, then each r is said to be an unbiased estimate of ρ. The distribution of r is called the sampling distribution of the sample correlation, and its standard deviation is called the standard error (SE). The SE of r can be calculated as

where N is the sample size. Notably, as N increases, SE decreases.
A confidence interval (CI) is the portion of the sampling distribution into which a statistic (e.g., r) will fall a prescribed percentage of the time. For example, a 95% CI means that a statistic will fall between the interval's lower and upper limits 95% of the time. The limits for the 95% CI can be calculated as follows:
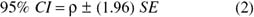
If a 99% CI were desired, the value 2.58 would be substituted for 1.96. These two levels of CI are those most commonly used in practice.
Let us compute CI using ρ= .35, N = 100, the common assumption that the distribution of r is normal, and Equation 1, SE = (1 − .352)/√100 = .088. Using Equation 2, the lower limit is .35 − (1.96)(.088) = .178, and the upper limit is .35 + (1.96)(.088) = .472. This example CI can be interpreted as follows: If an infinite number of random samples of 100 each were drawn from the population of interest, 95% of the rs would fall between .178 and .472, and 5% would fall outside the CI.
...
- Foundations: History
- Army Alpha/Army Beta
- Hawthorne Studies/Hawthorne Effect
- History of Industrial/Organizational Psychology in Europe and the United Kingdom
- History of Industrial/Organizational Psychology in North America
- History of Industrial/Organizational Psychology in Other Parts of the World
- Human Relations Movement
- Project A
- Scientific Management
- Scientist-Practitioner Model
- Unions
- Foundations: Ethical and Legal Issues
- Adverse Impact/Disparate Treatment/Discrimination at Work
- Affirmative Action
- Age Discrimination in Employment Act
- Americans with Disabilities Act
- Bona Fide Occupational Qualifications
- Civil Rights Act of 1964, Civil Rights Act of 1991
- Comparable Worth
- Corporate Ethics
- Corporate Social Responsibility
- Employment at Will
- Equal Pay Act of 1963
- Ethics in Industrial/Organizational Practice
- Ethics in Industrial/Organizational Research
- Family and Medical Leave Act
- Glass Ceiling
- Labor Law
- National Institute for Occupational Safety and Health/Occupational Safety and Health Administration
- Race Norming
- Sexual Discrimination
- Sexual Harassment at Work
- Stereotyping
- Test Security
- Uniform Guidelines on Employee Selection Procedures
- Workplace Accommodations for the Disabled
- Foundations: Research Methods
- Benchmarking
- Case Study Method
- Competency Modeling
- Content Coding
- Critical Incident Technique
- Cross-Cultural Research Methods and Theory
- Experimental Designs
- Focus Groups
- Lens Model
- Linkage Research and Analyses
- Longitudinal Research/Experience Sampling Technique
- Meta-Analysis
- Naturalistic Observation
- Nonexperimental Designs
- Organizational Surveys
- Policy Capturing
- Program Evaluation
- Qualitative Research Approach
- Quantitative Research Approach
- Quasi-experimental Designs
- Sampling Techniques
- Simulation, Computer Approach
- Survey Approach
- Verbal Protocol Analysis
- Foundations: Measurement Theory and Statistics
- Classical Test Theory
- Confidence Intervals/Hypothesis Testing/Effect Sizes
- Construct
- Criterion Theory
- Descriptive Statistics
- Differential Item Functioning
- Factor Analysis
- Generalizability Theory
- Incremental Validity
- Inferential Statistics
- Item Response Theory
- Measurement Scales
- Measures of Association/Correlation Coefficient
- Moderator and Mediator Variables
- Multilevel Modeling
- Multilevel Modeling Techniques
- Multitrait–Multimethod Matrix
- Nomological Networks
- Normative versus Ipsative Measurement
- Reliability
- Statistical Power
- Structural Equation Modeling
- Utility Analysis
- Validation Strategies
- Validity
- Industrial Psychology: Understanding and Assessing Individual Differences
- Affective Traits
- Big Five Taxonomy of Personality
- Biographical Data
- Cognitive Abilities
- Cognitive Ability Tests
- Computer Assessment
- Core Self-Evaluations
- Emotional Intelligence
- Employment Interview
- Genetics and Industrial/Organizational Psychology
- Graphology
- Gravitational Hypothesis
- Hardiness
- Impression Management
- Individual Assessment
- Individual Differences
- Integrity Testing
- Job Knowledge Testing
- Letters of Recommendation
- Locus of Control
- Machiavellianism
- Motivational Traits
- Need for Achievement, Power, and Affiliation
- Optimism and Pessimism
- Personality
- Personality Assessment
- Physical Performance Assessment
- Practical Intelligence
- Protestant Work Ethic
- Self-Esteem
- Situational Judgment Tests
- Standardized Testing
- Stereotype Threat
- Trainability and Adaptability
- Type A and Type B Personalities
- Work Samples
- Work Values
- Industrial Psychology: Employment, Staffing, and Career Issues
- Dictionary of Occupational Titles
- Applicant/Test-Taker Reactions
- Banding
- Career Development
- Careers
- Compensation
- Credentialing
- Dirty Work
- Drug and Alcohol Testing
- Electronic Human Resources Management
- Employee Selection
- Executive Selection
- Exit Survey (Exit Interview)
- Expatriates
- Gainsharing and Profit Sharing
- Gay, Lesbian, and Bisexual Issues at Work
- Human Resources Strategy
- Job Advertisements
- Job Analysis
- Job Analysis Methods
- Job Choice
- Job Description
- Job Evaluation
- Job Search
- Job Typologies
- Occupational Information Network (O*NET)
- Older Worker Issues
- Person–Environment Fit
- Person–Job Fit
- Person–Organization Fit
- Person–Vocation Fit
- Placement and Classification
- Prescreening Assessment Methods for Personnel Selection
- Realistic Job Preview
- Recruitment
- Recruitment Sources
- Retirement
- Selection Strategies
- Selection: Occupational Tailoring
- Succession Planning
- Underemployment
- Industrial Psychology: Developing, Training, and Evaluating Employees
- 360-Degree Feedback
- Assessment Center
- Assessment Center Methods
- Distance Learning
- Diversity Training
- Electronic Performance Monitoring
- Employee Assistance Program
- Executive Coaching
- Feedback Seeking
- Frame-of-Reference Training
- Leadership Development
- Mentoring
- Organizational Socialization
- Organizational Socialization Tactics
- Performance Appraisal
- Performance Appraisal, Objective Indexes
- Performance Appraisal, Subjective Indexes
- Performance Feedback
- Rating Errors and Perceptual Biases
- Self-Fulfilling Prophecy: Pygmalion Effect
- Socialization: Employee Proactive Behaviors
- Training
- Training Evaluation
- Training Methods
- Training Needs Assessment and Analysis
- Transfer of Training
- Industrial Psychology: Productive and Counterproductive Employee Behavior
- Contextual Performance/Prosocial Behavior/Organizational Citizenship Behavior
- Counterproductive Work Behaviors
- Counterproductive Work Behaviors, Interpersonal Deviance
- Counterproductive Work Behaviors, Organizational Deviance
- Creativity at Work
- Customer Satisfaction with Services
- Cyberloafing at Work
- Innovation
- Integrity at Work
- Job Performance Models
- Organizational Retaliatory Behavior
- Theft at Work
- Time Management
- Violence at Work
- Whistle-Blowers
- Withdrawal Behaviors, Absenteeism
- Withdrawal Behaviors, Lateness
- Withdrawal Behaviors, Turnover
- Workplace Incivility
- Industrial Psychology: Motivation and Job Design
- Action Theory
- Control Theory
- Empowerment
- Expectancy Theory of Work Motivation
- Goal-Setting Theory
- Human–Computer Interaction
- Incentives
- Intrinsic and Extrinsic Work Motivation
- Job Characteristics Theory
- Job Design
- Job Involvement
- Job Rotation
- Job Sharing
- Need Theories of Work Motivation
- Path–Goal Theory
- Positive Psychology Applied to Work
- Self-Concept Theory of Work Motivation
- Self-Efficacy
- Self-Regulation Theory
- Social Cognitive Theory
- Telecommuting
- Theory of Work Adjustment
- Two-Factor Theory
- Work Motivation
- Workaholism
- Industrial Psychology: Leadership and Management
- Abusive Supervision
- Behavioral Approach to Leadership
- Charismatic Leadership Theory
- Employee Grievance Systems
- Global Leadership and Organizational Behavior Effectiveness Project
- Implicit Theory of Leadership
- Judgment and Decision-Making Process
- Judgment and Decision-Making Process: Advice Giving and Taking
- Judgment and Decision-Making Process: Heuristics, Cognitive Biases, and Contextual Influences
- Leader–Member Exchange Theory
- Leadership and Supervision
- Least Preferred Coworker Theory
- Life-cycle Model of Leadership
- Normative Models of Decision Making and Leadership
- Reinforcement Theory of Work Motivation
- Situational Approach to Leadership
- Spirituality and Leadership at Work
- Trait Approach to Leadership
- Transformational and Transactional Leadership
- Trust
- Industrial Psychology: Groups, Teams, and Working with Others
- Conflict at Work
- Conflict Management
- Diversity in the Workplace
- Group Cohesiveness
- Group Decision-Making Quality and Performance
- Group Decision-Making Techniques
- Group Development
- Group Dynamics and Processes
- Groups
- Groupthink
- Input–Process–Output Model of Team Effectiveness
- Intergroup Relations
- Interpersonal Communication
- Interpersonal Communication Styles
- Justice in Teams
- Meetings at Work
- Negotiation, Mediation, and Arbitration
- Networking
- Social Exchange Theory
- Social Loafing
- Social Norms and Conformity
- Social Support
- Team Building
- Team Mental Model
- Team-Based Rewards
- Virtual Teams
- Workplace Romance
- Industrial Psychology: Employee Well-Being and Attitudes
- Affective Events Theory
- Attitudes and Beliefs
- Boredom at Work
- Emotional Burnout
- Emotional Labor
- Emotions
- Eustress
- Job Satisfaction
- Job Satisfaction Measurement
- Job Security/Insecurity
- Mood
- Morale
- Organizational Commitment
- Organizational Cynicism
- Organizational Justice
- Psychological Contract
- Quality of Work Life
- Role Ambiguity
- Role Conflict
- Role Overload and Underload
- Stress, Consequences
- Stress, Coping and Management
- Stress, Models and Theories
- Theory of Reasoned Action/Theory of Planned Behavior
- Union Commitment
- Work–Life Balance
- Industrial Psychology: Organizational Structure, Design, and Change
- Attraction–Selection–Attrition Model
- Automation/Advanced Manufacturing Technology/Computer-Based Integrated Technology
- Balanced Scorecard
- Compressed Workweek
- Downsizing
- Entrepreneurship
- Flexible Work Schedules
- Globalization
- High-Performance Organization Model
- Learning Organizations
- Mergers, Acquisitions, and Strategic Alliances
- Organizational Behavior
- Organizational Behavior Management
- Organizational Change
- Organizational Change, Resistance to
- Organizational Climate
- Organizational Communication, Formal
- Organizational Communication, Informal
- Organizational Culture
- Organizational Development
- Organizational Image
- Organizational Politics
- Organizational Sensemaking
- Organizational Structure
- Outsourcing
- Shiftwork
- Sociotechnical Approach
- Strategic Planning
- Survivor Syndrome
- Terrorism and Work
- Theory of Action
- Total Quality Management
- Virtual Organizations
- Workplace Injuries
- Workplace Safety
- Professional Organizations and Related Fields
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches