Entry
Reader's guide
Entries A-Z
Subject index
Analysis of Variance
Analysis of variance (ANOVA) is a method for decomposing variance in a measured outcome into variance that can be explained, such as by a regression model or an experimental treatment assignment, and variance that cannot be explained, which is often attributable to random error. Using this decomposition into component sums of squares, certain test statistics can be calculated that can be used to describe the data or even justify model selection. Lab experiments have become increasingly popular in political science, and ANOVA is a useful tool for analyzing such experiments. In recent years, there have been a number of laboratory experiments on the effects of campaigning and media advertising. Nicolas Valentino, Vincent Hutchings, and Ismail White (2002), Diana Mutz and Byron Reeves (2005), and Ted Brader (2005) have all performed lab experiments that aim to determine the effect that campaigning and advertising in media have on voters views and decisions. All three experiments employ an ANOVA to control for observable characteristics, interactions between treatment regimes, and significance of the relative effectiveness of treatments. This entry discusses ANOVA and its applications in greater detail.
In the familiar regression context, the “sum of squares” (SS) can be decomposed as follows. Assuming that Yi is individual i's outcome, 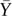 is the mean of the outcomes, Ŷi is individual i's fitted value based on the ordinary least squares (OLS) estimates, and ei is the resulting residual,
is the mean of the outcomes, Ŷi is individual i's fitted value based on the ordinary least squares (OLS) estimates, and ei is the resulting residual,
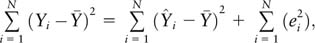
where
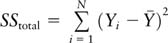
is the total sum of squares,
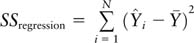
refers to the variance explained by the regression, and
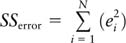
is the variance due to the error term, also known as the unexplained variance. Commonly, we would write this decomposition as

The equations above show how the total variance in the observations can be decomposed into variance that can be explained by the regression equation and variance that can be attributed to the random error term in the regression model.
ANOVA is not restricted to use with regression models. The concept of decomposing variance can be applied to other models of data, such as an experimental model. The following is the decomposition of a one-way layout experimental design in which an experimenter randomly assigns observations to one of I treatment assignments. Each treatment assignment has J observations assigned to it. In the case of a randomized controlled trial with only one treatment regime and N subjects randomly assigned to treatment with half a probability, this would mean that I = 2, one treated group and one control group, where each group has size J. In this framework, the variance decomposition would be as follows:
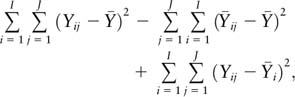
where
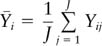
is defined as the average response under the Ith treatment and
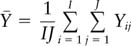
is defined as the overall average of all observations, regardless of treatment assignment. Commonly, this sum of squares expression is written as

where SSbetween refers to the part of the variance that can be attributed to the different treatment assignments and SSwithin refers to the variance that can be described by the random error within a treatment assignment. From this, we can see that SSbetween and SSregression, from the regression framework, both refer to the explained variance. SSwithin and SSerror both refer to the unexplained variance.
...
- Comparative Politics, Theory, and Methods
- Anarchism
- Anarchy
- Breakdown of Political Systems
- Cabinets
- Censorship
- Central Banks
- Change, Institutional
- Charisma
- Citizenship
- Collaboration
- Comparative Methods
- Comparative Politics
- Competition, Political
- Conditionality
- Constitutional Engineering
- Corporativism
- Decentralization
- Democracy, Types of
- Discursive Institutionalism
- Elites
- Environmental Issues
- Executive
- Government
- Historical Sociology
- Human Rights, Comparative Perspectives
- Hybrid Regimes
- Institutionalization
- Institutionalization
- Institutions and Institutionalism
- Interest Groups
- Irredentism
- Labor Movement
- Leadership
- Legitimacy
- Military Rule
- Monarchy
- Neo-Patrimonialism
- Neo-Weberian State
- Oligarchy
- Path Dependence
- Personalization of Politics
- Pillarization
- Political Integration
- Political Science, International
- Political Systems, Types
- Politics of Language
- Presidentialism
- Prospect Theory
- Qualitative Comparative Analysis
- Referenda
- Reform
- Regime (Comparative Politics)
- Regionalism
- Regionalization
- Representation
- Republic
- Republicanism
- Responsibility
- Responsiveness
- Revolution
- Rule of Law
- Secession
- Semipresidentialism
- Separation of Powers
- Social Movements
- Socialist Systems
- Stability
- State
- State, Virtual
- Terrorist Groups
- Totalitarian Regimes
- Welfare Policies
- Welfare State
- Case and Area Studies
- Area Studies
- Authoritarian Regimes
- Case Studies
- Caudillismo
- Communist Systems
- Comparative Methods
- Comparative Politics
- Cross-National Surveys
- Democracy: Chinese Perspectives
- Democracy: Middle East Perspectives
- Democracy: Russian Perspectives
- Fascist Movements
- Multiculturalism
- Populist Movements
- Postcommunist Regimes
- Regional Integration (Supranational)
- Subnational Governments
- Democracy and Democratization
- Accountability
- Accountability, Electoral
- Accountability, Interinstitutional
- Change, Institutional
- Citizenship
- Civil Service
- Coalitions
- Collaboration
- Colonialism
- Competition, Political
- Conditionality
- Constitutional Engineering
- Constitutionalism
- Corruption, Administrative
- Credible Commitment
- Democracy, Direct
- Democracy, Quality
- Democracy, Types of
- Democracy: Chinese Perspectives
- Democracy: Middle East Perspectives
- Democracy: Russian Perspectives
- Democratization
- Developing World and International Relations
- Development Administration
- Development, Political
- Empowerment
- Federalism
- Foreign Aid and Development
- Governance
- Governance, Good
- Groupthink
- Human Development
- Liberalization
- Modernization Theory
- Monarchy
- Nation Building
- Opposition
- Peasants' Movements
- Pluralist Interest Intermediation
- Postcolonialism
- Postmaterialism
- Representation
- Responsibility
- Responsiveness
- Responsiveness of Bureaucracy
- Rule of Law
- Self-Determination
- Semipresidentialism
- State Collapse
- State Failure
- State Formation
- Sustainable Development
- Traditional Rule
- Transition
- Transitional Justice
- Decision Making in Democracies
- Cost–Benefit Analysis
- Delegation
- Deliberative Policy Making
- Election by Lot
- Election Observation
- Election Research
- Elections, Primary
- Elections, Volatility
- Electoral Behavior
- Electoral Campaigns
- Electoral Geography
- Electoral Systems
- Electoral Turnout
- Executive
- Judicial Independence
- Judicial Systems
- Lobbying
- Parliamentary Systems
- Parliaments
- Participation
- Participation, Contentious
- Referenda
- Separation of Powers
- Voting Rules, Electoral, Effects of
- Voting Rules, Legislative
- Epistemological Foundations
- Behavioralism
- Biology and Politics
- Causality
- Concept Formation
- Conditions, Necessary and Sufficient
- Constructivism
- Constructivism in International Relations
- Critical Theory
- Critical Theory in International Relations
- Culturalism
- Democracy, Theories of
- Epistemic Communities
- Epistemological and Methodological Foundations
- Ethics
- Feminist Theory in International Relations
- Functionalism
- Historical Sociology
- Idealism
- Ideology
- Institutional Theory
- Institutions and Institutionalism
- Logic of Appropriateness
- Methodology
- Multiculturalism
- Neoliberal Institutionalism
- Neoliberalism
- Paradigms in Political Science
- Positivism
- Quantitative Versus Qualitative Methods
- Rationalism, Critical
- Rationality, Bounded
- Systems Theory
- Utilitarianism
- Gender and Race/Ethnicity
- International Relations
- Balance of Power
- Colonialism
- Constructivism in International Relations
- Containment
- Critical Theory
- Critical Theory in International Relations
- Democratic Peace
- Dependency Theory
- Developing World and International Relations
- Domestic Politics and International Relations
- Empire
- Europe as an International Actor
- Foreign Aid and Development
- Foreign Policy Analysis
- Governance, Global
- Human Rights in International Relations
- Indigenous Peoples' Rights
- Intergovernmentalism
- International Law
- International Organizations
- International Regimes
- International Relations as a Field of Study
- International Relations, Theory
- International System
- International Trade
- Intervention
- Intervention, Humanitarian
- Judicialization of International Relations
- Mediation in International Relations
- Multilateralism
- Nongovernmental Organizations (NGOs)
- Normative Theory in International Relations
- Political Science, International Institutionalization
- Postmodernism in International Relations
- Psychological Explanations of International Politics
- Realism in International Relations
- Superpower
- Peace, War, and Conflict Resolution
- Alliances
- Arms Race
- Bilateralism
- Bipolarity and Multipolarity
- Civil War
- Collective Security
- Conflict Resolution
- Conflicts
- Détente
- Diplomacy
- Disarmament
- Domestic Politics and International Relations
- Empire
- Foreign Policy Analysis
- Genocide
- Imperialism
- Intervention
- Intervention, Humanitarian
- Judicial Decision Making
- Judicialization of International Relations
- Mediation in International Relations
- Militias
- Multilateralism
- National Interest
- Natural Resources
- Neutrality
- Pacifism
- Participation, Contentious
- Peace
- Peacekeeping
- Positive Peace
- Power and International Politics
- Preemptive War
- Psychological Explanations of International Politics
- Sanctions
- Secession
- Security and Defense Policy
- Security Cooperation
- Security Dilemma
- Sovereignty
- Strategic (Security) Studies
- Superpower
- Territory
- Terrorism, International
- Transatlantic Relations
- Unilateralism
- United Nations
- Violence
- War and Peace
- Warlords
- Westphalian Ideal State
- World Systems Theory
- Political Economy
- Capitalism
- Central Banks
- Class, Social
- Cost–Benefit Analysis
- Economic Policy
- Economic Statecraft
- Economic Theories of Politics
- Foreign Aid and Development
- Inequality, Economic
- International Monetary Fund (IMF)
- International Political Economy
- Labor Movement
- Market Economy
- Market Failure
- Monetary Relations
- Multilateralism
- Multinational Corporations (MNCs)
- Nongovernmental Organizations (NGOs)
- Policy, Employment
- Political Economy
- Privatization
- Property
- Protectionism
- Public Budgeting
- Public Employment
- Public Goods
- Redistribution
- Social Stratification
- Sustainable Development
- Tax Policy
- Trade Liberalization
- Traditional Rule
- Tragedy of the Commons
- Transaction Costs
- Transformation, Economic
- Welfare Policies
- Welfare State
- World Bank
- World Trade Organization (WTO)
- Political Parties
- Christian Democratic Parties
- Cleavages, Social and Political
- Communist Parties
- Conservative Parties
- Green Parties
- Liberal Parties
- One-Party Dominance
- Parties
- Party Finance
- Party Identification
- Party Linkage
- Party Manifesto
- Party Organization
- Party System Fragmentation
- Party Systems
- Social Democracy
- Socialist Parties
- Political Philosophy/Theory
- African Political Thought
- Anarchism
- Charisma
- Communism
- Communitarianism
- Conservatism
- Constitutionalism
- Contract Theory
- Democracy, Theories of
- Discursive Institutionalism
- Ethics
- Fascism
- Fundamentalism
- Greek Philosophy
- Idealism in International Relations
- Liberalism
- Liberalism in International Relations
- Libertarianism
- Liberty
- Maoism
- Marxism
- Mercantilism
- Nationalism
- Neoliberal Institutionalism
- Neoliberalism
- Normative Political Theory
- Normative Theory in International Relations
- Pacifism
- Pluralism
- Political Class
- Political Philosophy
- Political Psychology
- Political Theory
- Postmodernism in International Relations
- Realism in International Relations
- Revisionism
- Rights
- Secularism
- Socialism
- Stalinism
- Statism
- Theocracy
- Utilitarianism
- Utopianism
- Equality and Inequality
- Formal and Positive Theory
- Theorists
- Political Sociology
- Alienation
- Anomia
- Apathy
- Attitude Consistency
- Beliefs
- Civic Culture
- Civic Participation
- Corporativism
- Credible Commitment
- Diaspora
- Dissatisfaction, Political
- Elections, Primary
- Electoral Behavior
- Elitism
- Empowerment
- Hegemony
- Historical Memory
- Intellectuals
- International Public Opinion
- International Society
- Media, Electronic
- Media, Print
- Migration
- Mobilization, Political
- Neo-Corporatism
- Networks
- Nonstate Actors
- Participation
- Participation, Contentious
- Party Identification
- Patriotism
- Pillarization
- Political Communication
- Political Culture
- Political Socialization
- Political Sociology as a Field of Study
- Popular Culture
- Power
- Schema
- Script
- Social Capital
- Social Cohesion
- Social Dominance Orientation
- Solidarity
- Subject Culture
- Support, Political
- Tolerance
- Trust, Social
- Values
- Violence
- Public Policy
- Advocacy
- Advocacy Coalition Framework
- Agencies
- Agenda Setting
- Bargaining
- Common Goods
- Complexity
- Compliance
- Contingency Theory
- Cooperation
- Coordination
- Crisis Management
- Deregulation
- Discretion
- Discursive Policy Analysis
- Environmental Policy
- Environmental Security Studies
- Europeanization of Policy
- Evidence-Based Policy
- Immigration Policy
- Impacts, Policy
- Implementation
- Joint-Decision Trap
- Judicial Decision Making
- Judicial Review
- Legalization of Policy
- Metagovernance
- Monitoring
- Neo-Weberian State
- New Public Management
- Organization Theory
- Policy Advice
- Policy Analysis
- Policy Community
- Policy Cycle
- Policy Evaluation
- Policy Formulation
- Policy Framing
- Policy Instruments
- Policy Learning
- Policy Network
- Policy Process, Models of
- Policy, Constructivist Models
- Policy, Discourse Models
- Policy, Employment
- Prospect Theory
- Reorganization
- Risk and Public Policy
- Self-Regulation
- Soft Law
- Stages Model of Policy Making
- Think Tanks
- Tragedy of the Commons
- Transaction Costs
- Public Administration
- Administration
- Administration Theory
- Audit Society
- Auditing
- Autonomy, Administrative
- Budgeting, Rational Models
- Bureaucracy
- Bureaucracy, Rational Choice Models
- Bureaucracy, Street-Level
- Civil Service
- Corruption, Administrative
- Effectiveness, Bureaucratic
- Governance
- Governance Networks
- Governance, Administration Policies
- Governance, Informal
- Governance, Multilevel
- Governance, Urban
- Groupthink
- Health Policy
- Intelligence
- Pay for Performance
- Performance
- Performance Management
- Planning
- Police
- Politicization of Bureaucracy
- Politicization of Civil Service
- Public Budgeting
- Public Employment
- Public Goods
- Public Office, Rewards
- Regulation
- Representative Bureaucracy
- Responsiveness of Bureaucracy
- Secret Services
- Security Apparatus
- Qualitative Methods
- Analytic Narratives: Applications
- Analytic Narratives: The Method
- Configurational Comparative Methods
- Data, Textual
- Discourse Analysis
- Ethnographic Methods
- Evaluation Research
- Fuzzy-Set Analysis
- Grounded Theory
- Hermeneutics
- Interviewing
- Interviews, Elite
- Interviews, Expert
- Mixed Methods
- Network Analysis
- Participant Observation
- Process Tracing
- Qualitative Comparative Analysis
- Quantitative Versus Qualitative Methods
- Thick Description
- Triangulation
- Quantitative Methods
- Aggregate Data Analysis
- Analysis of Variance
- Boolean Algebra
- Categorical Response Data
- Censored and Truncated Data
- Cohort Analysis
- Correlation
- Correspondence Analysis
- Cross-National Surveys
- Cross-Tabular Analysis
- Data Analysis, Exploratory
- Data Visualization
- Data, Archival
- Data, Missing
- Data, Spatial
- Event Counts
- Event History Analysis
- Experiments, Field
- Experiments, Laboratory
- Experiments, Natural
- Factor Analysis
- Fair Division
- Fuzzy-Set Analysis
- Granger Causality
- Graphics, Statistical
- Hypothesis Testing
- Inference, Ecological
- Interaction Effects
- Item–Response (Rasch) Models
- Logit and Probit Analyses
- Matching
- Maximum Likelihood
- Measurement
- Measurement, Levels
- Measurement, Scales
- Meta-Analysis
- Misspecification
- Mixed Methods
- Model Specification
- Models, Computational/Agent-Based
- Monte Carlo Methods
- Multilevel Analysis
- Nonlinear Models
- Nonparametric Methods
- Panel Data Analysis
- Political Risk Analysis
- Prediction and Forecasting
- Quantitative Methods, Basic Assumptions
- Quantitative Versus Qualitative Methods
- Regression
- Robust Statistics
- Sampling, Random and Nonrandom
- Scaling
- Scaling Methods: A Taxonomy
- Selection Bias
- Simultaneous Equation Modeling
- Statistical Inference, Classical and Bayesian
- Statistical Significance
- Statistics: Overview
- Structural Equation Modeling
- Survey Research
- Survey Research Modes
- Time-Series Analysis
- Time-Series Cross-Section Data and Methods
- Triangulation
- Variables
- Variables, Instrumental
- Weighted Least Squares
- Religion
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches