Entry
Reader's guide
Entries A-Z
Subject index
Outliers
Outliers refers to atypical and infrequent observations that differ markedly from the bulk of observations (in location, scale, or distributional pattern). An observed outlier may be caused by the error in measurement or processing, influenced by an interruptive event (such as strike, natural disaster, political or economic crises), or generated by a different mechanism. Although an outlier may not necessarily be “wrong,” the effect of outliers on inference procedures can be substantial: A small number of outliers may have a disproportionate influence on the estimated value of the correlation coefficients or the slope of the regression line (see Figure 1); the real efficiency of optimal statistical methods could be reduced; and the resultant inference from the statistical data analysis could be unreliable or even invalid.
Outlier detection is important for effective data analysis and modeling. Various methods can be used to detect outliers in data analysis (such as histogram, boxplot, and scatterplot). If outliers are detected, they should not be simply excluded from the data set. It is important to find out whether they represent a purely random phenomenon or whether they indicate some misspecification in the systematic part of the model. In some cases, an outlier may be corrected by error control in measurement or recording. In the case of a highly asymmetric data distribution, an outlier may become a normal observation after a data transformation.
Figure 1 The Effects of Outlier on the Slope Coefficients of Linear
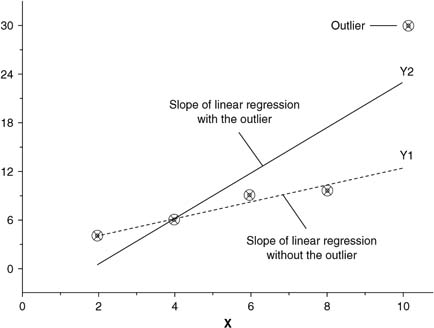
In most cases, the outliers are the most interesting observations in the data set, since they may reveal some unusual and interesting phenomenon. A thorough investigation of outliers will help achieve a better understanding of the data structure and more confidence in data modeling. To control the excessive influence of outliers, resistant methods (such as weighted-median polish) may be used in exploratory data analysis to help identify data structure, and robust methods (such as robust regression) may be used in confirmatory data analysis to produce efficient parameter estimates. Some methods available through geovisualization, such as brushing and linking, are useful means for exploring outliers.
Further Readings
- Analytical Methods
- Analytical Cartography
- Cartographic Modeling
- Cost Surface
- Cost-Benefit Analysis
- Data Mining, Spatial
- Density
- Diffusion
- Ecological Fallacy
- Effects, First- and Second-Order
- Error Propagation
- Exploratory Spatial Data Analysis (ESDA)
- Fragmentation
- Geocoding
- Geodemographics
- Geographical Analysis Machine (GAM)
- Geographically Weighted Regression (GWR)
- Georeferencing, Automated
- Geostatistics
- Geovisualization
- Image Processing
- Interpolation
- Intervisibility
- Kernel
- Location-Allocation Modeling
- Minimum Bounding Rectangle
- Modifiable Areal Unit Problem (MAUP)
- Multicriteria Evaluation
- Multidimensional Scaling (MDS)
- Multivalued Logic
- Network Analysis
- Optimization
- Outliers
- Pattern Analysis
- Polygon Operations
- Qualitative Analysis
- Regionalized Variables
- Slope Measures
- Spatial Analysis
- Spatial Autocorrelation
- Spatial Econometrics
- Spatial Filtering
- Spatial Interaction
- Spatial Statistics
- Spatial Weights
- Spatialization
- Spline
- Structured Query Language (SQL)
- Terrain Analysis
- Cartography and Visualization
- Analytical Cartography
- Cartograms
- Cartography
- Choropleth Map
- Classification, Data
- Datum
- Generalization, Cartographic
- Geovisualization
- Isoline
- Legend
- Multiscale Representations
- Multivariate Mapping
- National Map Accuracy Standards (NMAS)
- Normalization
- Projection
- Scale
- Shaded Relief
- Symbolization
- Three-Dimensional Visualization
- Tissot's Indicatrix
- Topographic Map
- Virtual Environments
- Visual Variables
- Conceptual Foundations
- Accuracy
- Aggregation
- Cognitive Science
- Direction
- Discrete versus Continuous Phenomena
- Distance
- Elevation
- Extent
- First Law of Geography
- Fractals
- Geographic Information Science (GISci)
- Geographic Information Systems (GIS)
- Geometric Primitives
- Isotropy
- Layer
- Logical Expressions
- Mathematical Model
- Mental Map
- Metaphor, Spatial and Map
- Nonstationarity
- Ontology
- Precision
- Representation
- Sampling
- Scale
- Scales of Measurement
- Semantic Interoperability
- Semantic Network
- Spatial Autocorrelation
- Spatial Cognition
- Spatial Heterogeneity
- Spatial Reasoning
- Spatial Relations, Qualitatitve
- Topology
- Uncertainty and Error
- Data Manipulation
- Data Modeling
- z-Values
- Computer-Aided Drafting (CAD)
- Data Modeling
- Data Structures
- Database Management System (DBMS)
- Database, Spatial
- Digital Elevation Model (DEM)
- Discrete versus Continuous Phenomena
- Elevation
- Extensible Markup Language (XML)
- Geometric Primitives
- Index, Spatial
- Integrity Constraints
- Layer
- Linear Referencing
- Network Data Structures
- Object Orientation (OO)
- Open Standards
- Raster
- Scalable Vector Graphics (SVG)
- Spatiotemporal Data Models
- Structured Query Language (SQL)
- Tessellation
- Three-Dimensional GIS
- Topology
- Triangulated Irregular Networks (TIN)
- Virtual Reality Modeling Language (VRML)
- Design Aspects
- Geocomputation
- Geospatial Data
- Accuracy
- Address Standard, U.S.
- Attributes
- BLOB
- Cadastre
- Census
- Census, U.S.
- Computer-Aided Drafting (CAD)
- Coordinate Systems
- Data Integration
- Datum
- Digital Chart of the World (DCW)
- Digital Elevation Model (DEM)
- Framework Data
- Gazetteers
- Geodesy
- Geodetic Control Framework
- Geography Markup Language (GML)
- Geoparsing
- Georeference
- Global Positioning System (GPS)
- Interoperability
- LiDAR
- Linear Referencing
- Metadata, Geospatial
- Metes and Bounds
- Minimum Mapping Unit (MMU)
- National Map Accuracy Standards (NMAS)
- Natural Area Coding System (NACS)
- Photogrammetry
- Postcodes
- Precision
- Projection
- Remote Sensing
- Scale
- Semantic Network
- Spatial Data Server
- Standards
- State Plane Coordinate System
- TIGER
- Topographic Map
- Universal Transverse Mercator (UTM)
- Organizational and Institutional Aspects
- Address Standard, U.S.
- Association of Geographic Information Laboratories for Europe (AGILE)
- Canada Geographic Information System (CGIS)
- Census, U.S.
- Chorley Report
- Coordination of Information on the Environment (CORINE)
- COSIT Conference Series
- Data Access Policies
- Data Warehouse
- Digital Chart of the World (DCW)
- Digital Earth
- Digital Library
- Distributed GIS
- Enterprise GIS
- Environmental Systems Research Institute, Inc. (ESRI)
- ERDAS
- Experimental Cartography Unit (ECU)
- Federal Geographic Data Committee (FGDC)
- Framework Data
- Geomatics
- Geospatial Intelligence
- GIS/LIS Consortium and Conference Series
- Google Earth
- GRASS
- Harvard Laboratory for Computer Graphics and Spatial Analysis
- IDRISI
- Intergraph
- Interoperability
- Land Information Systems
- Life Cycle
- Location-Based Services (LBS)
- Manifold GIS
- MapInfo
- Metadata, Geospatial
- MicroStation
- National Center for Geographic Information and Analysis (NCGIA)
- National Geodetic Survey (NGS)
- National Mapping Agencies
- Open Geospatial Consortium (OGC)
- Open Source Geospatial Foundation (OSGF)
- Open Standards
- Ordnance Survey (OS)
- Quantitative Revolution
- Software, GIS
- Spatial Data Infrastructure
- Spatial Decision Support Systems
- Standards
- U.S. Geological Survey (USGS)
- University Consortium for Geographic Information Science (UCGIS)
- Web GIS
- Web Service
- Societal Issues
- Access to Geographic Information
- Copyright and Intellectual Property Rights
- Critical GIS
- Cybergeography
- Data Access Policies
- Digital Library
- Economics of Geographic Information
- Ethics in the Profession
- Geographic Information Law
- Historical Studies, GIS for
- Liability Associated With Geographic Information
- Licenses, Data and Software
- Location-Based Services (LBS)
- Privacy
- Public Participation GIS (PPGIS)
- Qualitative Analysis
- Quantitative Revolution
- Spatial Literacy
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches