Entry
Reader's guide
Entries A-Z
Subject index
Modeling Causal Learning
Humans display remarkable ability to acquire causal knowledge. Hume's philosophical analysis of causation set the agenda for discovering how causal relations can be inferred from observable data, including temporal order and covariations among events. Recent computational modeling work on causal learning has made extensive use of formalisms based on directed causal graphs (Figure 1). Within a causal graph, each arrow connects a node representing a cause to an effect node, reflecting core assumptions that a cause precedes its effect and has some power to generate or prevent it. The computational goal is to infer from the observable data the unobservable causal structure conveyed by the graph and the magnitude of the power of each cause to influence its effect.
Figure 1 A simple example of a causal graph
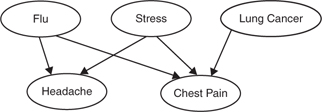
This entry covers some key issues that arise in modeling human causal learning. Alternative models of causal learning vary depending on the assumptions adopted in the computation, the goal of the computation, and the presentation format of the input data. Understanding models from these perspectives can clarify their commonalities and differences, guide the design of psychological experiments to test the validity of key assumptions, and assess whether models can potentially be extended to real-life problems, such as medical diagnosis and scientific discovery.
Alternative Causal Assumptions
When the causal graph includes multiple potential causes of a single effect, two leading classes of models make different assumptions about the integration rule used to combine causal influences. One class (including the classic delta-P model and the associative Rescorla-Wagner model) assumes a linear integration rule: Each candidate cause changes the probability of the effect by a constant amount regardless of the presence or absence of other causes. A second class is represented by the power PC theory, a theory of causal judgments postulating that learners assume that unobservable causal influences operate independently to produce the effect. Guided by this assumption, causal integration is based on probabilistic versions of various logical operators, such as OR and AND-NOT, chosen to reflect the polarity of causal influence (i.e., whether a cause produces or prevents the occurrence of an effect).
When the causal graph includes multiple effects of a single cause (e.g., flu causes headache and chest pain, as shown in Figure 1), the causal Markov assumption states that the probability of one effect occurring is independent of the probability of other effects occurring, given that its own direct causes are present. Statistical models that examine causal relationships adopt the Markov assumption, which guides exploration of conditional independencies that hold in a body of data, thereby constraining the search space by eliminating highly unlikely cause-effect relations. The extent to which humans employ the causal Markov assumption remains controversial.
When observations are limited, human causal learning relies heavily on some type of prior knowledge. Prior knowledge can be specific to a domain (based on known categories), but it can also include abstract assumptions about properties of a system of cause-effect relations (e.g., preference for causal networks that exhibit various types of simplicity). Use of appropriate prior knowledge can explain the rapid acquisition of causal relations often exhibited by humans.
...
- Action and Motor Control
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Attention
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Concepts and Categories
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Consciousness
- Aphasia
- Attitude Change
- Attitude Change
- Attitudes and Behavior
- Attraction
- Attribution Theory
- Auditory Masking
- Behavioral Therapy
- Borderline Personality Disorder
- Cognitive Dissonance
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Common Coding
- Conduction Aphasia
- Consciousness, Comparative Perspectives
- Deductive Reasoning
- Depth Perception
- Desirable Difficulties Perspective on Learning
- Discrimination Learning, Training Methods
- Disorders and Pathology
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Evolutionary Perspectives
- Exercise and the Brain
- Face Perception
- Facial Expressions, Emotional
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Group Decision Making
- Hearing
- Heritability
- Intergroup Conflict
- Intergroup Conflict, Models of
- Learning Styles
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Love
- McCollough Effect
- Meta-Analysis
- Metacognition and Education
- Motor Learning, Practical Aspects
- Multinomial Modeling
- Music Perception
- Neural Basis
- Optic Flow
- Perceptual Consciousness and Attention
- Perceptual Constancy
- Personal Identity, Development of
- Personality: Individual Versus Situation Debate
- Personality: Individual Versus Situation Debate
- Persuasion
- Philosophical Perspectives
- Placebo Effect
- Political Psychology
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Political Psychology
- Psychological Research
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Reaction Time
- Retrieval Practice (Testing) Effect
- Semantic Dementia
- Skill Learning, Enhancement of
- Social Cognition
- Social Loafing
- Spacing Effect, Practical Applications
- Speech Perception
- Stereopsis
- Subliminal Perception
- Synesthesia
- Time Perception
- Unconscious Perception
- Visual Imagery
- Visual Masking
- Visual Search
- Visuospatial Reasoning
- Wisdom of Crowds Effect
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory, Evolution of
- Decision Making
- Amnesia
- Argument Mapping
- Behavioral Therapy
- Behaviorism
- Case-Based Reasoning, Computational Perspectives
- Computational Perspectives
- Desirable Difficulties Perspective on Learning
- Desire
- Desire
- Emotion and Psychopathology
- Emotion, Cerebral Lateralization
- Emotion, Psychophysiology of
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Genes and Linguistic Tone
- Human Classification Learning
- Implicit Memory
- Learning Styles
- Memory, Neural Basis
- Metacognition and Education
- Music and the Evolution of Language
- Neural Basis
- Philosophical Perspectives
- Placebo Effect
- Practical Applications
- Psychological Research
- Reinforcement Learning, Psychological Perspectives
- Retrieval Practice (Testing) Effect
- Skill Learning, Enhancement of
- Spacing Effect
- Word Learning
- Disorders and Pathology
- Addiction
- Amnesia
- Analogical Mapping and Reasoning
- Anchoring
- Anosognosia
- Anxiety Disorders
- Aphasia
- Aphasia
- Apraxia
- Autism
- Automatic Behavior
- Autoscopic Phenomena
- Availability Heuristic
- Behavioral Therapy
- Borderline Personality Disorder
- Capgras Delusion
- Causal Theories of Memory
- Conduction Aphasia
- Conduction Aphasia
- Confabulation
- Delusions
- Desire
- Distributed Cognition
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Emotion and Psychopathology
- Emotions and Consciousness
- Fregoli Delusion
- Hypochondria
- Intentionality of Emotion
- Legal Reasoning, Psychological Perspectives
- Memory and Knowledge
- Motivated Thinking
- Narcissistic Personality Disorder
- Objects of Memory
- Rationality of Emotion
- Religion and Psychiatry
- Representativeness Heuristic
- Schizophrenia
- Scientific Reasoning
- Semantic Dementia
- Spatial Cognition, Development of
- Thinking
- Two System Models of Reasoning
- Visual Imagery
- Visuospatial Reasoning
- Williams Syndrome
- Computational Perspectives
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Cultural Perspectives
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Disorders and Pathology
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Evolutionary Perspectives
- Aphasia
- Attitude Change
- Attitude Change
- Attitudes and Behavior
- Attraction
- Attribution Theory
- Auditory Masking
- Behavioral Therapy
- Borderline Personality Disorder
- Cognitive Dissonance
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Common Coding
- Conduction Aphasia
- Consciousness, Comparative Perspectives
- Deductive Reasoning
- Depth Perception
- Desirable Difficulties Perspective on Learning
- Discrimination Learning, Training Methods
- Disorders and Pathology
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Evolutionary Perspectives
- Exercise and the Brain
- Face Perception
- Facial Expressions, Emotional
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Group Decision Making
- Hearing
- Heritability
- Intergroup Conflict
- Intergroup Conflict, Models of
- Learning Styles
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Love
- McCollough Effect
- Meta-Analysis
- Metacognition and Education
- Motor Learning, Practical Aspects
- Multinomial Modeling
- Music Perception
- Neural Basis
- Optic Flow
- Perceptual Consciousness and Attention
- Perceptual Constancy
- Personal Identity, Development of
- Personality: Individual Versus Situation Debate
- Personality: Individual Versus Situation Debate
- Persuasion
- Philosophical Perspectives
- Placebo Effect
- Political Psychology
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Political Psychology
- Psychological Research
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Reaction Time
- Retrieval Practice (Testing) Effect
- Semantic Dementia
- Skill Learning, Enhancement of
- Social Cognition
- Social Loafing
- Spacing Effect, Practical Applications
- Speech Perception
- Stereopsis
- Subliminal Perception
- Synesthesia
- Time Perception
- Unconscious Perception
- Visual Imagery
- Visual Masking
- Visual Search
- Visuospatial Reasoning
- Wisdom of Crowds Effect
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory, Evolution of
- Neural Basis
- Amnesia
- Argument Mapping
- Behavioral Therapy
- Behaviorism
- Case-Based Reasoning, Computational Perspectives
- Computational Perspectives
- Desirable Difficulties Perspective on Learning
- Desire
- Desire
- Emotion and Psychopathology
- Emotion, Cerebral Lateralization
- Emotion, Psychophysiology of
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Genes and Linguistic Tone
- Human Classification Learning
- Implicit Memory
- Learning Styles
- Memory, Neural Basis
- Metacognition and Education
- Music and the Evolution of Language
- Neural Basis
- Philosophical Perspectives
- Placebo Effect
- Practical Applications
- Psychological Research
- Reinforcement Learning, Psychological Perspectives
- Retrieval Practice (Testing) Effect
- Skill Learning, Enhancement of
- Spacing Effect
- Word Learning
- Philosophical Perspectives
- Addiction
- Amnesia
- Analogical Mapping and Reasoning
- Anchoring
- Anosognosia
- Anxiety Disorders
- Aphasia
- Aphasia
- Apraxia
- Autism
- Automatic Behavior
- Autoscopic Phenomena
- Availability Heuristic
- Behavioral Therapy
- Borderline Personality Disorder
- Capgras Delusion
- Causal Theories of Memory
- Conduction Aphasia
- Conduction Aphasia
- Confabulation
- Delusions
- Desire
- Distributed Cognition
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Emotion and Psychopathology
- Emotions and Consciousness
- Fregoli Delusion
- Hypochondria
- Intentionality of Emotion
- Legal Reasoning, Psychological Perspectives
- Memory and Knowledge
- Motivated Thinking
- Narcissistic Personality Disorder
- Objects of Memory
- Rationality of Emotion
- Religion and Psychiatry
- Representativeness Heuristic
- Schizophrenia
- Scientific Reasoning
- Semantic Dementia
- Spatial Cognition, Development of
- Thinking
- Two System Models of Reasoning
- Visual Imagery
- Visuospatial Reasoning
- Williams Syndrome
- Psychological Research
- Affective Forecasting
- Anxiety Disorders
- Attention and Emotion
- Cognitive Dissonance
- Descriptions
- Descriptive Thought
- Disgust
- Embarrassment
- Emotion and Moral Judgment
- Emotion and Working Memory
- Emotion Regulation
- Emotion, Psychophysiology of
- Emotion, Structural Approaches
- Envy
- Exercise and the Brain
- Facial Expressions, Emotional
- Guilt
- Happiness
- Indexical Thought
- Intension and Extension
- Jealousy
- Love
- Metaphor
- Mnemonic Strategies
- Object-Dependent Thought
- Regret
- Religion and Psychiatry
- Resentment
- Retrieval Practice (Testing) Effect
- Spacing Effect, Practical Applications
- Unconscious Emotions, Psychological Perspectives
- Philosophical Perspectives
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Psychological Research
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Heritability
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Cultural Perspectives
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Philosophical Perspectives
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Psychological Research
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Neural Basis
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Psychological Research
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Computational Perspectives
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Cultural Perspectives
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Development
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Disorders and Pathology
- Aphasia
- Attitude Change
- Attitude Change
- Attitudes and Behavior
- Attraction
- Attribution Theory
- Auditory Masking
- Behavioral Therapy
- Borderline Personality Disorder
- Cognitive Dissonance
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Common Coding
- Conduction Aphasia
- Consciousness, Comparative Perspectives
- Deductive Reasoning
- Depth Perception
- Desirable Difficulties Perspective on Learning
- Discrimination Learning, Training Methods
- Disorders and Pathology
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Evolutionary Perspectives
- Exercise and the Brain
- Face Perception
- Facial Expressions, Emotional
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Group Decision Making
- Hearing
- Heritability
- Intergroup Conflict
- Intergroup Conflict, Models of
- Learning Styles
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Love
- McCollough Effect
- Meta-Analysis
- Metacognition and Education
- Motor Learning, Practical Aspects
- Multinomial Modeling
- Music Perception
- Neural Basis
- Optic Flow
- Perceptual Consciousness and Attention
- Perceptual Constancy
- Personal Identity, Development of
- Personality: Individual Versus Situation Debate
- Personality: Individual Versus Situation Debate
- Persuasion
- Philosophical Perspectives
- Placebo Effect
- Political Psychology
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Political Psychology
- Psychological Research
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Reaction Time
- Retrieval Practice (Testing) Effect
- Semantic Dementia
- Skill Learning, Enhancement of
- Social Cognition
- Social Loafing
- Spacing Effect, Practical Applications
- Speech Perception
- Stereopsis
- Subliminal Perception
- Synesthesia
- Time Perception
- Unconscious Perception
- Visual Imagery
- Visual Masking
- Visual Search
- Visuospatial Reasoning
- Wisdom of Crowds Effect
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory, Evolution of
- Evolutionary Perspectives
- Amnesia
- Argument Mapping
- Behavioral Therapy
- Behaviorism
- Case-Based Reasoning, Computational Perspectives
- Computational Perspectives
- Desirable Difficulties Perspective on Learning
- Desire
- Desire
- Emotion and Psychopathology
- Emotion, Cerebral Lateralization
- Emotion, Psychophysiology of
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Genes and Linguistic Tone
- Human Classification Learning
- Implicit Memory
- Learning Styles
- Memory, Neural Basis
- Metacognition and Education
- Music and the Evolution of Language
- Neural Basis
- Philosophical Perspectives
- Placebo Effect
- Practical Applications
- Psychological Research
- Reinforcement Learning, Psychological Perspectives
- Retrieval Practice (Testing) Effect
- Skill Learning, Enhancement of
- Spacing Effect
- Word Learning
- Neural Basis
- Addiction
- Amnesia
- Analogical Mapping and Reasoning
- Anchoring
- Anosognosia
- Anxiety Disorders
- Aphasia
- Aphasia
- Apraxia
- Autism
- Automatic Behavior
- Autoscopic Phenomena
- Availability Heuristic
- Behavioral Therapy
- Borderline Personality Disorder
- Capgras Delusion
- Causal Theories of Memory
- Conduction Aphasia
- Conduction Aphasia
- Confabulation
- Delusions
- Desire
- Distributed Cognition
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Emotion and Psychopathology
- Emotions and Consciousness
- Fregoli Delusion
- Hypochondria
- Intentionality of Emotion
- Legal Reasoning, Psychological Perspectives
- Memory and Knowledge
- Motivated Thinking
- Narcissistic Personality Disorder
- Objects of Memory
- Rationality of Emotion
- Religion and Psychiatry
- Representativeness Heuristic
- Schizophrenia
- Scientific Reasoning
- Semantic Dementia
- Spatial Cognition, Development of
- Thinking
- Two System Models of Reasoning
- Visual Imagery
- Visuospatial Reasoning
- Williams Syndrome
- Philosophical Perspectives
- Affective Forecasting
- Anxiety Disorders
- Attention and Emotion
- Cognitive Dissonance
- Descriptions
- Descriptive Thought
- Disgust
- Embarrassment
- Emotion and Moral Judgment
- Emotion and Working Memory
- Emotion Regulation
- Emotion, Psychophysiology of
- Emotion, Structural Approaches
- Envy
- Exercise and the Brain
- Facial Expressions, Emotional
- Guilt
- Happiness
- Indexical Thought
- Intension and Extension
- Jealousy
- Love
- Metaphor
- Mnemonic Strategies
- Object-Dependent Thought
- Regret
- Religion and Psychiatry
- Resentment
- Retrieval Practice (Testing) Effect
- Spacing Effect, Practical Applications
- Unconscious Emotions, Psychological Perspectives
- Practical Applications
- Aging, Memory, and Information Processing Speed
- Deception, Linguistic Cues to
- Divided Attention and Memory
- Emotion and Working Memory
- Event Memory, Development
- Exercise and the Brain
- Eyewitness Memory
- Implicit Memory
- Intelligence and Working Memory
- Lie Detection
- Memory Recall, Dynamics
- Memory, Interference With
- Rehearsal and Memory
- Retrieval Practice (Testing) Effect
- Semantic Memory
- Spacing Effect
- Visual Working Memory
- Working Memory
- Working Memory in Language Processing
- Psychological Research
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Cohort Model of Auditory Word Recognition
- Compound Words, Processing of
- Concepts and Language
- Conceptual Combination
- Conversation and Dialogue
- Declarative/Procedural Model of Language
- Discourse Processing, Models of
- Disfluencies: Comprehension Processes
- Eye Movements During Reading
- Frequency Effects in Word Recognition
- Gesture and Language Processing
- Inferences in Language Comprehension
- Inner Speech
- Language Development
- Language Production, Agreement in
- Language Production, Incremental Processing in
- Lie Detection
- Metaphor
- Perspective Taking in Language Processing
- Planning in Language Production
- Production of Language
- Prosody in Production
- Speech Perception
- Syntactic Production, Agreement in
- Word Learning
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory in Language Processing
- Computational Perspectives
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Development
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Neural Basis
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Practical Applications
- Aphasia
- Attitude Change
- Attitude Change
- Attitudes and Behavior
- Attraction
- Attribution Theory
- Auditory Masking
- Behavioral Therapy
- Borderline Personality Disorder
- Cognitive Dissonance
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Common Coding
- Conduction Aphasia
- Consciousness, Comparative Perspectives
- Deductive Reasoning
- Depth Perception
- Desirable Difficulties Perspective on Learning
- Discrimination Learning, Training Methods
- Disorders and Pathology
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Evolutionary Perspectives
- Exercise and the Brain
- Face Perception
- Facial Expressions, Emotional
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Group Decision Making
- Hearing
- Heritability
- Intergroup Conflict
- Intergroup Conflict, Models of
- Learning Styles
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Love
- McCollough Effect
- Meta-Analysis
- Metacognition and Education
- Motor Learning, Practical Aspects
- Multinomial Modeling
- Music Perception
- Neural Basis
- Optic Flow
- Perceptual Consciousness and Attention
- Perceptual Constancy
- Personal Identity, Development of
- Personality: Individual Versus Situation Debate
- Personality: Individual Versus Situation Debate
- Persuasion
- Philosophical Perspectives
- Placebo Effect
- Political Psychology
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Political Psychology
- Psychological Research
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Reaction Time
- Retrieval Practice (Testing) Effect
- Semantic Dementia
- Skill Learning, Enhancement of
- Social Cognition
- Social Loafing
- Spacing Effect, Practical Applications
- Speech Perception
- Stereopsis
- Subliminal Perception
- Synesthesia
- Time Perception
- Unconscious Perception
- Visual Imagery
- Visual Masking
- Visual Search
- Visuospatial Reasoning
- Wisdom of Crowds Effect
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory, Evolution of
- Psychological Research
- Amnesia
- Argument Mapping
- Behavioral Therapy
- Behaviorism
- Case-Based Reasoning, Computational Perspectives
- Computational Perspectives
- Desirable Difficulties Perspective on Learning
- Desire
- Desire
- Emotion and Psychopathology
- Emotion, Cerebral Lateralization
- Emotion, Psychophysiology of
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Genes and Linguistic Tone
- Human Classification Learning
- Implicit Memory
- Learning Styles
- Memory, Neural Basis
- Metacognition and Education
- Music and the Evolution of Language
- Neural Basis
- Philosophical Perspectives
- Placebo Effect
- Practical Applications
- Psychological Research
- Reinforcement Learning, Psychological Perspectives
- Retrieval Practice (Testing) Effect
- Skill Learning, Enhancement of
- Spacing Effect
- Word Learning
- Computational Perspectives
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Development
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Disorders and Pathology
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Evolutionary Perspectives
- Aphasia
- Attitude Change
- Attitude Change
- Attitudes and Behavior
- Attraction
- Attribution Theory
- Auditory Masking
- Behavioral Therapy
- Borderline Personality Disorder
- Cognitive Dissonance
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Common Coding
- Conduction Aphasia
- Consciousness, Comparative Perspectives
- Deductive Reasoning
- Depth Perception
- Desirable Difficulties Perspective on Learning
- Discrimination Learning, Training Methods
- Disorders and Pathology
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Evolutionary Perspectives
- Exercise and the Brain
- Face Perception
- Facial Expressions, Emotional
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Group Decision Making
- Hearing
- Heritability
- Intergroup Conflict
- Intergroup Conflict, Models of
- Learning Styles
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Love
- McCollough Effect
- Meta-Analysis
- Metacognition and Education
- Motor Learning, Practical Aspects
- Multinomial Modeling
- Music Perception
- Neural Basis
- Optic Flow
- Perceptual Consciousness and Attention
- Perceptual Constancy
- Personal Identity, Development of
- Personality: Individual Versus Situation Debate
- Personality: Individual Versus Situation Debate
- Persuasion
- Philosophical Perspectives
- Placebo Effect
- Political Psychology
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Political Psychology
- Psychological Research
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Reaction Time
- Retrieval Practice (Testing) Effect
- Semantic Dementia
- Skill Learning, Enhancement of
- Social Cognition
- Social Loafing
- Spacing Effect, Practical Applications
- Speech Perception
- Stereopsis
- Subliminal Perception
- Synesthesia
- Time Perception
- Unconscious Perception
- Visual Imagery
- Visual Masking
- Visual Search
- Visuospatial Reasoning
- Wisdom of Crowds Effect
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory, Evolution of
- Neural Basis
- Amnesia
- Argument Mapping
- Behavioral Therapy
- Behaviorism
- Case-Based Reasoning, Computational Perspectives
- Computational Perspectives
- Desirable Difficulties Perspective on Learning
- Desire
- Desire
- Emotion and Psychopathology
- Emotion, Cerebral Lateralization
- Emotion, Psychophysiology of
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Genes and Linguistic Tone
- Human Classification Learning
- Implicit Memory
- Learning Styles
- Memory, Neural Basis
- Metacognition and Education
- Music and the Evolution of Language
- Neural Basis
- Philosophical Perspectives
- Placebo Effect
- Practical Applications
- Psychological Research
- Reinforcement Learning, Psychological Perspectives
- Retrieval Practice (Testing) Effect
- Skill Learning, Enhancement of
- Spacing Effect
- Word Learning
- Philosophical Perspectives
- Addiction
- Amnesia
- Analogical Mapping and Reasoning
- Anchoring
- Anosognosia
- Anxiety Disorders
- Aphasia
- Aphasia
- Apraxia
- Autism
- Automatic Behavior
- Autoscopic Phenomena
- Availability Heuristic
- Behavioral Therapy
- Borderline Personality Disorder
- Capgras Delusion
- Causal Theories of Memory
- Conduction Aphasia
- Conduction Aphasia
- Confabulation
- Delusions
- Desire
- Distributed Cognition
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Emotion and Psychopathology
- Emotions and Consciousness
- Fregoli Delusion
- Hypochondria
- Intentionality of Emotion
- Legal Reasoning, Psychological Perspectives
- Memory and Knowledge
- Motivated Thinking
- Narcissistic Personality Disorder
- Objects of Memory
- Rationality of Emotion
- Religion and Psychiatry
- Representativeness Heuristic
- Schizophrenia
- Scientific Reasoning
- Semantic Dementia
- Spatial Cognition, Development of
- Thinking
- Two System Models of Reasoning
- Visual Imagery
- Visuospatial Reasoning
- Williams Syndrome
- Practical Applications
- Affective Forecasting
- Anxiety Disorders
- Attention and Emotion
- Cognitive Dissonance
- Descriptions
- Descriptive Thought
- Disgust
- Embarrassment
- Emotion and Moral Judgment
- Emotion and Working Memory
- Emotion Regulation
- Emotion, Psychophysiology of
- Emotion, Structural Approaches
- Envy
- Exercise and the Brain
- Facial Expressions, Emotional
- Guilt
- Happiness
- Indexical Thought
- Intension and Extension
- Jealousy
- Love
- Metaphor
- Mnemonic Strategies
- Object-Dependent Thought
- Regret
- Religion and Psychiatry
- Resentment
- Retrieval Practice (Testing) Effect
- Spacing Effect, Practical Applications
- Unconscious Emotions, Psychological Perspectives
- Psychological Research
- Aging, Memory, and Information Processing Speed
- Deception, Linguistic Cues to
- Divided Attention and Memory
- Emotion and Working Memory
- Event Memory, Development
- Exercise and the Brain
- Eyewitness Memory
- Implicit Memory
- Intelligence and Working Memory
- Lie Detection
- Memory Recall, Dynamics
- Memory, Interference With
- Rehearsal and Memory
- Retrieval Practice (Testing) Effect
- Semantic Memory
- Spacing Effect
- Visual Working Memory
- Working Memory
- Working Memory in Language Processing
- Philosophical Perspectives
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Neural Basis
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Philosophical Perspectives
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Practical Applications
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Psychological Research
- Aphasia
- Attitude Change
- Attitude Change
- Attitudes and Behavior
- Attraction
- Attribution Theory
- Auditory Masking
- Behavioral Therapy
- Borderline Personality Disorder
- Cognitive Dissonance
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Common Coding
- Conduction Aphasia
- Consciousness, Comparative Perspectives
- Deductive Reasoning
- Depth Perception
- Desirable Difficulties Perspective on Learning
- Discrimination Learning, Training Methods
- Disorders and Pathology
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Evolutionary Perspectives
- Exercise and the Brain
- Face Perception
- Facial Expressions, Emotional
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Group Decision Making
- Hearing
- Heritability
- Intergroup Conflict
- Intergroup Conflict, Models of
- Learning Styles
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Love
- McCollough Effect
- Meta-Analysis
- Metacognition and Education
- Motor Learning, Practical Aspects
- Multinomial Modeling
- Music Perception
- Neural Basis
- Optic Flow
- Perceptual Consciousness and Attention
- Perceptual Constancy
- Personal Identity, Development of
- Personality: Individual Versus Situation Debate
- Personality: Individual Versus Situation Debate
- Persuasion
- Philosophical Perspectives
- Placebo Effect
- Political Psychology
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Political Psychology
- Psychological Research
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Reaction Time
- Retrieval Practice (Testing) Effect
- Semantic Dementia
- Skill Learning, Enhancement of
- Social Cognition
- Social Loafing
- Spacing Effect, Practical Applications
- Speech Perception
- Stereopsis
- Subliminal Perception
- Synesthesia
- Time Perception
- Unconscious Perception
- Visual Imagery
- Visual Masking
- Visual Search
- Visuospatial Reasoning
- Wisdom of Crowds Effect
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory, Evolution of
- Philosophical Perspectives
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Development
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Philosophical Perspectives
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Psychological Research
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Computational Perspectives
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Neural Basis
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Philosophical Perspectives
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Psychological Research
- Aphasia
- Attitude Change
- Attitude Change
- Attitudes and Behavior
- Attraction
- Attribution Theory
- Auditory Masking
- Behavioral Therapy
- Borderline Personality Disorder
- Cognitive Dissonance
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Common Coding
- Conduction Aphasia
- Consciousness, Comparative Perspectives
- Deductive Reasoning
- Depth Perception
- Desirable Difficulties Perspective on Learning
- Discrimination Learning, Training Methods
- Disorders and Pathology
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Evolutionary Perspectives
- Exercise and the Brain
- Face Perception
- Facial Expressions, Emotional
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Group Decision Making
- Hearing
- Heritability
- Intergroup Conflict
- Intergroup Conflict, Models of
- Learning Styles
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Love
- McCollough Effect
- Meta-Analysis
- Metacognition and Education
- Motor Learning, Practical Aspects
- Multinomial Modeling
- Music Perception
- Neural Basis
- Optic Flow
- Perceptual Consciousness and Attention
- Perceptual Constancy
- Personal Identity, Development of
- Personality: Individual Versus Situation Debate
- Personality: Individual Versus Situation Debate
- Persuasion
- Philosophical Perspectives
- Placebo Effect
- Political Psychology
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Political Psychology
- Psychological Research
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Reaction Time
- Retrieval Practice (Testing) Effect
- Semantic Dementia
- Skill Learning, Enhancement of
- Social Cognition
- Social Loafing
- Spacing Effect, Practical Applications
- Speech Perception
- Stereopsis
- Subliminal Perception
- Synesthesia
- Time Perception
- Unconscious Perception
- Visual Imagery
- Visual Masking
- Visual Search
- Visuospatial Reasoning
- Wisdom of Crowds Effect
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory, Evolution of
- Development
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Disorders and Pathology
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Philosophical Perspectives
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Psychological Research
- Aphasia
- Attitude Change
- Attitude Change
- Attitudes and Behavior
- Attraction
- Attribution Theory
- Auditory Masking
- Behavioral Therapy
- Borderline Personality Disorder
- Cognitive Dissonance
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Common Coding
- Conduction Aphasia
- Consciousness, Comparative Perspectives
- Deductive Reasoning
- Depth Perception
- Desirable Difficulties Perspective on Learning
- Discrimination Learning, Training Methods
- Disorders and Pathology
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Evolutionary Perspectives
- Exercise and the Brain
- Face Perception
- Facial Expressions, Emotional
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Group Decision Making
- Hearing
- Heritability
- Intergroup Conflict
- Intergroup Conflict, Models of
- Learning Styles
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Love
- McCollough Effect
- Meta-Analysis
- Metacognition and Education
- Motor Learning, Practical Aspects
- Multinomial Modeling
- Music Perception
- Neural Basis
- Optic Flow
- Perceptual Consciousness and Attention
- Perceptual Constancy
- Personal Identity, Development of
- Personality: Individual Versus Situation Debate
- Personality: Individual Versus Situation Debate
- Persuasion
- Philosophical Perspectives
- Placebo Effect
- Political Psychology
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Political Psychology
- Psychological Research
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Reaction Time
- Retrieval Practice (Testing) Effect
- Semantic Dementia
- Skill Learning, Enhancement of
- Social Cognition
- Social Loafing
- Spacing Effect, Practical Applications
- Speech Perception
- Stereopsis
- Subliminal Perception
- Synesthesia
- Time Perception
- Unconscious Perception
- Visual Imagery
- Visual Masking
- Visual Search
- Visuospatial Reasoning
- Wisdom of Crowds Effect
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory, Evolution of
- Development
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Disorders and Pathology
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Philosophical Perspectives
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Psychological Research
- Aphasia
- Attitude Change
- Attitude Change
- Attitudes and Behavior
- Attraction
- Attribution Theory
- Auditory Masking
- Behavioral Therapy
- Borderline Personality Disorder
- Cognitive Dissonance
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Common Coding
- Conduction Aphasia
- Consciousness, Comparative Perspectives
- Deductive Reasoning
- Depth Perception
- Desirable Difficulties Perspective on Learning
- Discrimination Learning, Training Methods
- Disorders and Pathology
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Evolutionary Perspectives
- Exercise and the Brain
- Face Perception
- Facial Expressions, Emotional
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Group Decision Making
- Hearing
- Heritability
- Intergroup Conflict
- Intergroup Conflict, Models of
- Learning Styles
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Love
- McCollough Effect
- Meta-Analysis
- Metacognition and Education
- Motor Learning, Practical Aspects
- Multinomial Modeling
- Music Perception
- Neural Basis
- Optic Flow
- Perceptual Consciousness and Attention
- Perceptual Constancy
- Personal Identity, Development of
- Personality: Individual Versus Situation Debate
- Personality: Individual Versus Situation Debate
- Persuasion
- Philosophical Perspectives
- Placebo Effect
- Political Psychology
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Political Psychology
- Psychological Research
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Reaction Time
- Retrieval Practice (Testing) Effect
- Semantic Dementia
- Skill Learning, Enhancement of
- Social Cognition
- Social Loafing
- Spacing Effect, Practical Applications
- Speech Perception
- Stereopsis
- Subliminal Perception
- Synesthesia
- Time Perception
- Unconscious Perception
- Visual Imagery
- Visual Masking
- Visual Search
- Visuospatial Reasoning
- Wisdom of Crowds Effect
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory, Evolution of
- Computational Perspectives
- Action and Bodily Movement
- Analogical Reasoning, Models of Development
- Anomalous Monism
- Anomalous Monism
- Anti-Individualism About Cognition
- Anti-Individualism About Cognition
- Attention and Emotions, Computational Perspectives
- Belief and Judgment
- Case-Based Reasoning, Computational Perspectives
- Causal Theories of Intentionality
- Causal Theories of Memory
- Computational Models of Emotion
- Computational Perspectives
- Conscious Thinking
- Conscious Thinking
- Consciousness and Embodiment
- Consciousness and Embodiment
- Consciousness and the Unconscious
- Deductive Reasoning
- Descriptive Thought
- Development
- Disorders and Pathology
- Disorders and Pathology
- Distributed Cognition
- Electrophysiological Studies of Mind
- Eliminative Materialism
- Eliminative Materialism
- Emergence
- Emergence
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Experimental Philosophy
- Explanatory Gap
- Explanatory Gap
- Extended Mind
- Face Recognition in Humans and Computers
- Facial Expressions, Computational Perspectives
- Facial Expressions, Computational Perspectives
- Freedom of Action
- Idealism
- Idealism
- Intelligence, Neural Basis
- Intentionality of Bodily Sensation
- Intentionality of Emotion
- Introspection
- Know-How, Philosophical Perspectives
- Know-How, Philosophical Perspectives
- Knowledge by Acquaintance
- Machine Speech Recognition
- Memory and Knowledge
- Mental Action
- Mental Causation
- Mental Causation
- Mind-Body Problem
- Modeling Causal Learning
- Moral Development
- Multimodal Conversational Systems
- Naïve Realism
- Natural Language Generation
- Neural Basis
- Object-Dependent Thought
- Personal Identity
- Personal Identity, Development of
- Philosophical Perspectives
- Philosophy of Action
- Physicalism
- Physicalism
- Psychological Research
- Realism and Instrumentalism
- Realism and Instrumentalism
- Reductive Physicalism
- Reductive Physicalism
- Relationships, Development of
- Representational Theory of Mind
- Self-Knowledge
- Semantic Memory, Computational Perspectives
- Sequential Memory, Computational Perspectives
- Serial Order Memory, Computational Perspectives
- Smell, Philosophical Perspectives
- Taste, Philosophical Perspectives
- Teleology
- Teleology
- Theory of Appearing
- Cultural Perspectives
- Aging, Memory, and Information Processing Speed
- Audition, Neural Basis
- Bilingual Language Processing
- Bilingualism, Cognitive Benefits of
- Black English Vernacular (Ebonics)
- Blindsight
- Borderline Personality Disorder
- Capgras Delusion
- Character and Personality, Philosophical Perspectives
- Collective Action
- Common Coding
- Computational Perspectives
- Distributed Cognition
- Emotion and Moral Judgment
- Emotion, Cultural Perspectives
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Evolutionary Perspectives
- Experimental Philosophy
- Flynn Effect: Rising Intelligence Scores
- Gender Differences in Language and Language Use
- Gesture and Language Processing
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Heritability
- Heritage Language and Second Language Learning
- Intelligence and Working Memory
- Joint or Collective Intention
- Joint or Collective Intention
- Knowledge Acquisition in Development
- Mirror Neurons
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Multiple Intelligences Theory
- Narcissistic Personality Disorder
- Neural Basis
- Philosophical Perspectives
- Philosophy of Action
- Psychological Research
- Attention and Action
- Attention and Emotion
- Attention, Resource Models
- Attentional Blink Effect
- Automaticity
- Change Blindness
- Divided Attention and Memory
- Inattentional Blindness
- Inhibition of Return
- Mental Effort
- Multitasking and Human Performance
- Neurodynamics of Visual Search
- Perceptual Consciousness and Attention
- Psychological Refractory Period
- Stroop Effect
- Visual Search
- Self-Knowledge
- Synesthesia
- Visual Imagery
- Word Learning
- Development
- Amnesia
- Analogical Reasoning, Models of Development
- Anxiety Disorders
- Character and Personality, Philosophical Perspectives
- Computational Perspectives
- Confabulation
- Desire
- Development
- Disjunctive Theory of Perception
- Disorders and Pathology
- Dissent, Effects on Group Decisions
- Distributed Cognition
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Evolutionary Perspectives
- Exercise and the Brain
- Folk Psychology
- Group Decision Making
- Guilt
- Hearing, Philosophical Perspectives
- Heritage Language and Second Language Learning
- Human Classification Learning
- Innateness and Parameter Setting
- Intergroup Conflict
- Intergroup Conflict, Models of
- Knowledge Acquisition in Development
- Language Development
- Language Development, Overregulation in
- Moral Development
- Naïve Realism
- Neural Basis
- Philosophical Perspectives
- Political Psychology
- Prediction, Clinical Versus Actuarial
- Psychological Research
- Religion and Psychiatry
- Semantic Dementia
- Smell, Philosophical Perspectives
- Spatial Cognition, Development of
- Taste, Philosophical Perspectives
- Word Learning
- Philosophical Perspectives
- Aphasia
- Attitude Change
- Attitude Change
- Attitudes and Behavior
- Attraction
- Attribution Theory
- Auditory Masking
- Behavioral Therapy
- Borderline Personality Disorder
- Cognitive Dissonance
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Common Coding
- Conduction Aphasia
- Consciousness, Comparative Perspectives
- Deductive Reasoning
- Depth Perception
- Desirable Difficulties Perspective on Learning
- Discrimination Learning, Training Methods
- Disorders and Pathology
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Evolutionary Perspectives
- Exercise and the Brain
- Face Perception
- Facial Expressions, Emotional
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Group Decision Making
- Hearing
- Heritability
- Intergroup Conflict
- Intergroup Conflict, Models of
- Learning Styles
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Love
- McCollough Effect
- Meta-Analysis
- Metacognition and Education
- Motor Learning, Practical Aspects
- Multinomial Modeling
- Music Perception
- Neural Basis
- Optic Flow
- Perceptual Consciousness and Attention
- Perceptual Constancy
- Personal Identity, Development of
- Personality: Individual Versus Situation Debate
- Personality: Individual Versus Situation Debate
- Persuasion
- Philosophical Perspectives
- Placebo Effect
- Political Psychology
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Political Psychology
- Psychological Research
- Anesthesia and Awareness
- Attention and Consciousness
- Consciousness and the Unconscious
- Metacognition and Education
- Perceptual Consciousness and Attention
- Self-Consciousness
- Self-Knowledge
- Subliminal Perception
- Unconscious Emotions, Psychological Perspectives
- Unconscious Perception
- Voluntary Action, Illusion of
- Reaction Time
- Retrieval Practice (Testing) Effect
- Semantic Dementia
- Skill Learning, Enhancement of
- Social Cognition
- Social Loafing
- Spacing Effect, Practical Applications
- Speech Perception
- Stereopsis
- Subliminal Perception
- Synesthesia
- Time Perception
- Unconscious Perception
- Visual Imagery
- Visual Masking
- Visual Search
- Visuospatial Reasoning
- Wisdom of Crowds Effect
- Word Recognition, Auditory
- Word Recognition, Visual
- Working Memory, Evolution of
- Practical Applications
- Amnesia
- Argument Mapping
- Behavioral Therapy
- Behaviorism
- Case-Based Reasoning, Computational Perspectives
- Computational Perspectives
- Desirable Difficulties Perspective on Learning
- Desire
- Desire
- Emotion and Psychopathology
- Emotion, Cerebral Lateralization
- Emotion, Psychophysiology of
- Emotional Recognition, Neuropsychology of
- Event Memory, Development
- Genes and Linguistic Tone
- Human Classification Learning
- Implicit Memory
- Learning Styles
- Memory, Neural Basis
- Metacognition and Education
- Music and the Evolution of Language
- Neural Basis
- Philosophical Perspectives
- Placebo Effect
- Practical Applications
- Psychological Research
- Reinforcement Learning, Psychological Perspectives
- Retrieval Practice (Testing) Effect
- Skill Learning, Enhancement of
- Spacing Effect
- Word Learning
- Psychological Research
- Addiction
- Amnesia
- Analogical Mapping and Reasoning
- Anchoring
- Anosognosia
- Anxiety Disorders
- Aphasia
- Aphasia
- Apraxia
- Autism
- Automatic Behavior
- Autoscopic Phenomena
- Availability Heuristic
- Behavioral Therapy
- Borderline Personality Disorder
- Capgras Delusion
- Causal Theories of Memory
- Conduction Aphasia
- Conduction Aphasia
- Confabulation
- Delusions
- Desire
- Distributed Cognition
- Dyslexia, Acquired
- Dyslexia, Developmental
- Dyslexia, Phonological Processing in
- Emotion and Moral Judgment
- Emotion and Psychopathology
- Emotions and Consciousness
- Fregoli Delusion
- Hypochondria
- Intentionality of Emotion
- Legal Reasoning, Psychological Perspectives
- Memory and Knowledge
- Motivated Thinking
- Narcissistic Personality Disorder
- Objects of Memory
- Rationality of Emotion
- Religion and Psychiatry
- Representativeness Heuristic
- Schizophrenia
- Scientific Reasoning
- Semantic Dementia
- Spatial Cognition, Development of
- Thinking
- Two System Models of Reasoning
- Visual Imagery
- Visuospatial Reasoning
- Williams Syndrome
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches