Entry
Reader's guide
Entries A-Z
Subject index
Median
Quantitative research in educational psychology typically begins with a description of the sample of subjects. This initial stage of analysis focuses on describing the center, shape, and spread (dispersion) of the observed data points. Various measures are available for describing the center, shape, and spread of a distribution of observed data points. In most instances, the researcher begins by describing the center point or central tendency of the distribution. Measures of central tendency (center) include the mean, median, and mode. The median is an often-used measure of central tendency because of the desirable characteristics it possesses.
The median is technically defined as the data point that splits the distribution of data in equal halves. That is, half of the data points fall above the median and half of the data points fall below the median. For example, suppose a mathematics assessment is administered to a group of students and the median score is found to be 74. This indicates that 50% of the students scored better than 74 and 50% scored worse than 74. Thus, the median for a data set is equivalent to the 50th percentile.
Calculating the median is rather straightforward, particularly with a small number of observed data points. When done by hand, the median can be calculated by arranging a set of observed data points in ascending (or descending) order. For example, consider seven hypothetical scores on the aforementioned mathematics assessment:
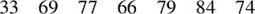
To calculate the median, the scores are first rearranged in ascending order,
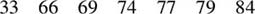
and the middle score is identified. In this case, half of the scores fall above a score of 74 and half fall below a score of 74.
In a distribution consisting of an even number of observed data points, there is no “true” median. Rather, the median is calculated as the average of the middle two scores. Reconsidering the previous example with an additional observation
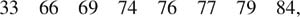
the centermost values are 74 and 76, which, when averaged, result in a median value of 75 (150/2).
A particularly desirable characteristic of the median is that it is unaffected by extreme or outlying data points. Unlike the mean, the median does not take into account the value of each data point in its calculation. Thus, the median often provides a more accurate representation of the center of a distribution of data points. To illustrate why this is so, reconsider the following data representing mathematics assessment scores for eight students:

This data set is fairly evenly distributed except for the lowest score of 33. This data point is 41 points lower than the median value of 74 and 33 points lower than the next smallest value of 66. When calculating the average or mean score, all of these data points are taken into consideration. The mean of the data set with the extreme observation is 69.75, whereas the mean without the extreme observation is75. On the other hand, the median score without the extreme observation does not change drastically. Whereas the median for the data set with the extreme observation is 75, the median without the extreme observation increases slightly to 76.
...
- Classroom Achievement
- Acceleration
- Alternative Academic Assessment
- Bell Curve
- Direct Instruction
- Educational Technology
- Failure, Effects of
- Gifted and Talented Students
- Goals
- Grade Retention
- Grading
- Halo Effect
- Home Environment and Academic Intrinsic Motivation
- Homework
- Intelligence and Intellectual Development
- Intelligence Quotient (IQ)
- Intelligence Tests
- Literacy
- Media Literacy
- Parental Expectations
- Personalized System of Instruction
- Precision Teaching
- Reading Comprehension Strategies
- Rubrics
- Spelling
- Test Anxiety
- Classroom Management
- Calculator Use
- Cheating
- Contingency Contracts
- Cooperative Learning
- Curriculum Development
- Discovery Learning
- Distance Learning
- Early Intervention Programs
- Educational Technology
- Effective Teaching, Characteristics of
- Mainstreaming
- Montessori Schools
- School Design
- School Resources
- Students' Rights
- Time-Out
- Token Reinforcement Programs
- Virtual Schools
- Vocational Education
- Cognitive Development
- Cognitive Development and School Readiness
- Conservation
- Deductive Reasoning
- Egocentrism
- Equilibration
- Field Independence–Field Dependence
- Flashbulb Memories, the Nature of
- Inductive Reasoning
- Intelligence and Intellectual Development
- Literacy
- Long-Term Memory
- Measurement and Cognitive Development
- Metacognition and Learning
- Moral Development
- Motivation and Emotion
- Object Permanence
- Perceptual Development
- Piaget's Theory of Cognitive Development
- Schemas
- Short-Term Memory
- Spelling
- Vygotsky's Cultural-Historical Theory of Development
- Zone of Proximal Development
- Ethnicity, Race, and Culture
- African Americans
- American Indians and Alaska Natives
- Asian Americans
- Bilingual Education
- Bilingualism
- Communication Disorders
- Cultural Deficit Model
- Cultural Diversity
- Culture
- Diversity
- Ethnicity and Race
- Head Start
- Hispanic Americans
- Identity Development
- Immigration
- Multicultural Classrooms
- Multicultural Education
- Families
- Gender and Gender Development
- Health and Well-Being
- Abstinence Education
- Athletics
- Attention Deficit Hyperactivity Disorder
- Autism Spectrum Disorders
- Behavior Disorders
- Brain-Relevant Education
- Communication Disorders
- Conduct Disorders
- Diagnostic and Statistical Manual of Mental Disorders
- Disabilities
- Drug Abuse
- Dyslexia
- Eating Disorders
- Extracurricular Activities
- HIV/AIDS
- Learning Disabilities
- Malnutrition and Development
- Mental Health Care in Schools
- Mental Retardation
- Obesity
- School Counseling
- Sex Education
- Special Education
- Suicide
- Human Development
- Acculturation
- Aggression
- Androgyny
- Anxiety
- Aptitude
- Athletics
- Attachment
- Attachment Disorder
- Autism Spectrum Disorders
- Behavior Disorders
- Creativity
- Early Intervention Programs
- Egocentrism
- Emotion and Memory
- Emotional Development
- Empathy
- Equilibration
- Erikson's Theory of Psychosocial Development
- Extracurricular Activities
- Friendship
- Gifted and Talented Students
- Head Start
- Identity Development
- Individual Differences
- Individuals with Disabilities Education Act
- Intelligence and Intellectual Development
- Intrinsic versus Extrinsic Motivation
- Kohlberg's Stages of Moral Development
- Mainstreaming
- Maslow's Hierarchy of Basic Needs
- Maturation
- Mental Retardation
- Metacognition and Learning
- Moral Development
- Motivation
- Motivation and Emotion
- Motor Development
- Myelination
- Neuroscience
- Peer Influences
- Perceptual Development
- Physical Development
- Piaget's Theory of Cognitive Development
- Risk Factors and Development
- School Violence and Disruption
- Self-Determination
- Self-Efficacy
- Self-Esteem
- Special Education
- Test Anxiety
- Vygotsky's Cultural-Historical Theory of Development
- Intelligence and Intellectual Development
- Language Development
- Learning and Memory
- Adult Learning
- Assistive Technology
- Aversive Stimuli
- Behavior Modification
- Bloom's Taxonomy of Educational Objectives
- Brain-Relevant Education
- Classical Conditioning
- Cognitive and Cultural Styles
- Cognitive View of Learning
- Cooperative Learning
- Discovery Learning
- Discrimination
- Distance Learning
- Divergent Thinking
- Educational Technology
- Emotion and Memory
- Episodic Memory
- Explicit Memory
- Flashbulb Memories, the Nature of
- Habituation
- Intrinsic versus Extrinsic Motivation
- Learning
- Learning Communities
- Learning Disabilities
- Learning Strategies
- Learning Style
- Lifelong Learning
- Long-Term Memory
- Malnutrition and Development
- Maturation
- Memory
- Metacognition and Learning
- Mnemonics
- Motivation and Emotion
- Observational Learning
- Older Learners
- Operant Conditioning
- Peer-Assisted Learning
- Perceptual Development
- Premack Principle
- Reinforcement
- Rosenthal Effect
- Shaping
- Short-Term Memory
- Social Learning Theory
- Stimulus Control
- Working Memory
- Organizations
- Peers and Peer Influences
- Public Policy
- Abstinence Education
- Assistive Technology
- Bilingual Education
- Charter Schools
- Child Abuse
- Early Child Care and Education
- English as a Second Language
- Ethics and Research
- Gangs
- Grade Retention
- Head Start
- High-Stakes Testing
- Home Education
- Immigration
- Inclusion
- Individualized Education Program
- Individuals with Disabilities Education Act
- Institutional Review Boards
- Intelligence Tests
- Least Restrictive Placement
- Mainstreaming
- No Child Left Behind
- Poverty
- School Design
- School Violence and Disruption
- Sex Education
- Special Education
- Students' Rights
- Testing
- Tracking
- Vouchers
- Research Methods and Statistics
- T Scores
- Case Studies
- Confidence Interval
- Correlation
- Cross-Sectional Research
- Descriptive Statistics
- Ethics and Research
- Ethnography
- Experimental Design
- External Validity
- Field Experiments
- Frequency Distribution
- Generalizability Theory
- Inferential Statistics
- Internal Validity
- Longitudinal Research
- Mean
- Median
- Meta-Analysis
- Mode
- Naturalistic Observation
- Normal Curve
- Percentile Rank
- Qualitative Research Methods
- Quantitative Research Methods
- Random Sample
- Regression
- Scientific Method
- Standard Deviation and Variance
- Standard Scores
- Stanine Scores
- Statistical Significance
- Social Development
- Teaching
- Aptitude Tests
- Constructivism
- Contingency Contracts
- Criterion-Referenced Testing
- Curriculum Development
- Direct Instruction
- Educational Technology
- Effective Teaching, Characteristics of
- Emotion and Memory
- English as a Second Language
- Evaluation
- Expert Teachers
- Explicit Teaching
- Goals
- Grade Retention
- Grade-Equivalent Scores
- Grading
- Home Education
- Homework
- Instructional Objectives
- Learning Objectives
- Parent–Teacher Conferences
- Personalized System of Instruction
- PRAXIS™
- Precision Teaching
- Rubrics
- Scaffolding
- School Readiness
- Sex Education
- Students' Rights
- Teaching Strategies
- Tracking
- Testing, Measurement, and Evaluation
- Acceleration
- Alternative Academic Assessment
- Aptitude Tests
- Assessment
- Bell Curve
- Certification
- Criterion-Referenced Testing
- Essay Tests
- Evaluation
- External Validity
- Generalizability Theory
- Grade Retention
- Grade-Equivalent Scores
- Grading
- High-Stakes Testing
- Intelligence Tests
- Measurement
- Measurement of Cognitive Development
- Mental Age
- Multiple-Choice Tests
- Norm-Referenced Tests
- Percentile Rank
- Personality Tests
- Reliability
- Rubrics
- Standardized Tests
- Stanford–Binet Test
- Test Anxiety
- Testing
- Validity
- Theory
- Applied Behavior Analysis
- Behavior Modification
- Bloom's Taxonomy of Educational Objectives
- Classical Conditioning
- Cognitive Behavior Modification
- Cognitive View of Learning
- Constructivism
- Continuity and Discontinuity in Learning
- Cultural Deficit Model
- Dynamical Systems
- Erikson's Theory of Psychosocial Development
- Generalizability Theory
- Kohlberg's Stages of Moral Development
- Learned Helplessness
- Maslow's Hierarchy of Basic Needs
- Neuroscience
- Piaget's Theory of Cognitive Development
- Premack Principle
- Psychoanalytic Theory
- Psychosocial Development
- Reciprocal Determinism
- Rosenthal Effect
- Schemas
- Social Learning Theory
- Theory of Mind
- Vicarious Reinforcement
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches