Entry
Entries A-Z
Subject index
Testing and Test Theory Development
In education, a test is a tool or technique intended to measure students' knowledge, intelligence, or ability. It usually consists of a series of questions, problems, or physical responses. A standardized test is a written test whose score is interpreted by reference to the scores of a norm group. An aptitude test ostensibly measures a person's “natural ability,” while the achievement test measures knowledge learned by the person. There are generally two types of questions in a test. First, there is the multiple-choice question. For a multiple-choice question, the test taker will check one or more of the choices in a list. Second is the free-response question. The free-response question requires the test taker to state an opinion or to write an essay or short answer. This latter type of question usually requires a deeper level of analytical thinking.
There are two branches to testing theory—classical test theory and the item response theory (IRT). The British psychologist Charles Spearman laid the foundation for the classical test theory, also called the true score model. The key concepts of classical test theory are reliability and validity. Reliability is the accuracy of the scores of a measure. A test is considered reliable if it allows for stable estimates of student ability. In other words, it achieves similar results for students who have similar ability and knowledge levels. On the other hand, a valid measure is one that is measuring what it is supposed to measure. Validity implies reliability (accuracy). A valid measure must be reliable, but a reliable measure need not be valid.
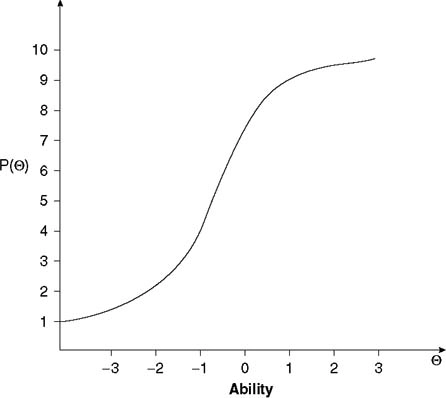
The essence of classical test theory is that any observed test score is the composite of two hypothetical components: a true score and a random error component.
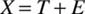
Where X is the observed score, T is the true score, and E is the error score.
In classical test theory, reliability is defined mathematically as the ratio of the variation of the true score and the variation of the observed score, which means how much of the variation in the observed score is explained by the variation of the true score. Or equivalently, reliability is defined as 1 minus the ratio of the variation of the error score and the variation of the observed score:
Figure 1. Item Characteristic Curve
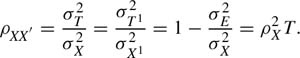
where ρXX′ is the symbol for the reliability of the observed score X, and σ2X, σ2T, σ2E are the variances of the observed, true, and error scores, respectively. We can see that the reliability coefficient can be mathematically defined as the ratio of true score variance to observed score variance.
IRT, also called latent trait theory, is a modern test theory. IRT requires stronger assumptions than classical test theory. First, a single common factor accounts for all item covariance. This common factor is the latent trait of interest, and there is a single latent trait. Second, relations between the latent trait and observed response have a specific form. The line relating the trait and response is called the item characteristic curve (ICC, see Figure 1).
In IRT, the latent trait is usually represented as theta ( ), as represented by the vertical axis in Figure 1. The vertical axis is the probability of getting the correct response. The ICC curve is usually represented by the logistic ICC.
...
- Loading...
Get a 30 day FREE TRIAL
-
 Watch videos from a variety of sources bringing classroom topics to life
Watch videos from a variety of sources bringing classroom topics to life -
Read modern, diverse business cases
-
Explore hundreds of books and reference titles

Read next

More like this
Sage Recommends
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches